

Yapay zeka çözümlerinizin beklediğiniz gibi çalıştığından nasıl emin oluyorsunuz?
AI Değerlendirmelerine Kısa Bir Giriş
Üretken Yapay Zeka (GenAI) hızla gelişiyor ve artık sadece eğlenceli sohbet robotları veya etkileyici görseller üretmekten ibaret değil. 2025, yapay zeka etrafındaki abartıların gerçek değere dönüştürülmesine odaklanılacak yıl olacak. Dünyanın dört bir yanındaki şirketler, kullanıcılara daha iyi hizmet sunmak, verimliliği artırmak, rekabet gücünü korumak ve büyümeyi teşvik etmek için GenAI'yı ürünlerine ve operasyonlarına entegre etmenin ve kullanmanın yollarını arıyor. Önde gelen sağlayıcıların API'leri ve önceden eğitilmiş modelleriyle GenAI'yi entegre etmek her zamankinden daha kolay görünüyor. Ama meselenin özü şu: Entegrasyonun kolay olması, yapay zeka çözümlerinin dağıtıldığında amaçlandığı gibi çalışacağı anlamına gelmiyor.

Tahmin modelleri aslında yeni bir şey değil: İnsanlar olarak yıllardır tahminlerde bulunuyoruz ve resmi olarak istatistiklerle başladık. Fakat, GenAI, birçok nedenden dolayı tahmin alanında devrim yaratıyor.:
- Yapay zeka çözümleri oluşturmak için kendi modelinizi eğitmenize veya veri bilimcisi olmanıza gerek yok.
- Yapay zeka artık sohbet arayüzleri aracılığıyla kullanımı kolay ve API'ler aracılığıyla entegrasyonu kolay.
- Daha önce yapılamayan veya yapılması gerçekten zor olan birçok şeyi açığa çıkarmak.
Bütün bunlar şunu yapar GenAI çok heyecan verici ama bir o kadar da riskli.. Geleneksel yazılımların veya klasik makine öğrenmesinin aksine, GenAI yeni bir düzeyde öngörülemezlik sunuyor. Deterministik bir mantık uygulamıyorsunuz, büyük miktarda veri üzerinde eğitilmiş bir model kullanıyorsunuz ve ihtiyaç duyulduğunda yanıt vereceğini umuyorsunuz. Peki bir yapay zeka sisteminin bizim istediğimiz şeyi yapıp yapmadığını nasıl anlarız? Çalıştırılmaya hazır olduğunu nasıl anlarız? Cevap, bu yazıda inceleyeceğimiz bir kavram olan değerlendirmelerdir:
- Genai sistemleri neden geleneksel yazılımlar veya hatta klasik makine öğrenimi (ML) ile aynı şekilde test edilemez?
- Derecelendirmelerin yapay zeka sisteminizin kalitesini anlamak için neden zorunlu olduğu ve isteğe bağlı olmadığı (sürprizlerden hoşlanmıyorsanız)
- Farklı değerlendirme türleri ve bunları pratikte uygulama teknikleri
İster ürün yöneticisi, ister mühendis veya yapay zekayla çalışan veya yapay zekaya ilgi duyan herhangi biri olun, umarım bu yazı yapay zeka sistemlerinin kalitesi hakkında eleştirel düşünmeyi anlamanıza yardımcı olur (ve bu kaliteye ulaşmak için değerlendirmelerin neden önemli olduğunu!).
Üretken yapay zeka, geleneksel yazılımlar veya klasik makine öğrenimi gibi test edilemez.
Geleneksel yazılım geliştirmedeSistemler deterministik bir mantığı takip eder: Eğer X olursa, Y de olur. - Her zaman. Platformunuzda bir sorun çıkmadığı veya kodunuzda bir hata oluşmadığı sürece... İşte bu yüzden testler, izleme ve uyarılar ekliyoruz. Birim testleri, küçük kod bloklarını doğrulamak, bileşenlerin birlikte iyi çalıştığından emin olmak için entegrasyon testleri ve üretimde bir şeyin bozulup bozulmadığını tespit etmek için izleme yapmak için kullanılır. Geleneksel yazılım testi, bir hesap makinesinin çalışmasını kontrol etmeye benzer. 2 + 2'yi girersiniz ve 4 beklersiniz. Açık ve kaçınılmazdır, doğru veya yanlış.
Ancak makine öğrenmesi ve yapay zeka belirsizlik ve olasılığı da beraberinde getiriyor. Davranışı kurallar aracılığıyla açıkça belirtmek yerine, verilerden kalıpları öğrenecek şekilde modeller eğitiyoruz. Yapay zekada, eğer X gerçekleşirse, çıktı artık sabit kodlanmış bir Y değil, modelin eğitim sırasında öğrendiklerine dayanan, belli bir olasılık derecesine sahip bir tahmindir.. Bu çok etkili olabilir, ancak aynı zamanda belirsizliğe de yol açar: aynı girdiler zaman içinde farklı çıktılara sahip olabilir, makul çıktılar aslında yanlış olabilir ve nadir senaryolarda beklenmeyen davranışlar ortaya çıkabilir...
Bu durum geleneksel test yöntemlerini yetersiz, hatta bazen uygulanamaz hale getiriyor. Hesap makinesi örneği, bir öğrencinin açık uçlu bir sınavdaki performansını değerlendirmeye benziyor. Her soru ve soruya verilebilecek birçok cevap yolu için verilen cevap doğru mu? Öğrencinin sahip olması gereken bilgi düzeyinin üstünde mi? Öğrenci her şeyi uyduruyor ama kulağa çok inandırıcı mı geliyor? Tıpkı bir sınavdaki cevaplar gibi, Yapay zeka sistemleri değerlendirilebilir, ancak farklı girdilere, bağlamlara ve kullanım durumlarına uyum sağlamak için daha genel ve esnek bir yola ihtiyaç duyarlar. (veya test türleri).
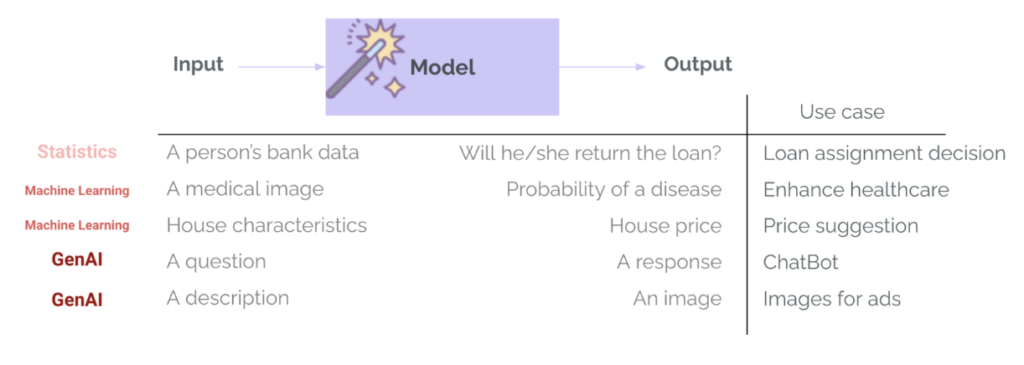
Içinde makine öğrenme Geleneksel olarak (ML), değerlendirmeler proje yaşam döngüsünün yerleşik bir parçasıdır.. Kredi onayı veya hastalık tespiti gibi dar bir görev için bir modeli eğitmek her zaman hassasiyet, geri çağırma, RMSE, MAE gibi ölçütleri kullanan bir değerlendirme adımı içerir. Bu, modelin ne kadar iyi performans gösterdiğini ölçmek, farklı model seçeneklerini karşılaştırmak ve modelin dağıtıma geçmek için yeterince iyi olup olmadığını belirlemek için kullanılır. GenAI'da bu durum genellikle değişir: Ekipler, daha önceden eğitilmiş ve model sağlayıcısı tarafından dahili olarak genel amaçlı değerlendirmelerden geçmiş ve kamuya açık kıyaslamalardan geçmiş modelleri kullanır. Bu modeller genel görevlerde (soruları yanıtlamak veya e-posta taslağı hazırlamak gibi) oldukça iyidir ve belirli kullanım durumumuz için bunlara aşırı güvenme riski vardır. Ancak şu soruyu sormak önemlidir:Bu harika şablon benim kullanım durumum için yeterince iyi mi?“İşte burada değerlendirme devreye giriyor.” - Tahminlerin veya üretimlerin belirli bir kullanım durumu, bağlam, girdiler ve kullanıcılar için iyi olup olmadığını değerlendirmek.

ML ile GenAI arasında bir diğer önemli fark ise modelin çıktısının çeşitliliği ve karmaşıklığıdır. Artık kategoriler ve olasılıklar (örneğin bir müşterinin krediyi geri ödeme olasılığı) veya sayılar (örneğin bir evin özelliklerine göre beklenen fiyatı) döndürmüyoruz. GenAI sistemleri farklı uzunluklarda, tonlarda, içeriklerde ve formatlarda pek çok çıktı türü döndürebilir. Benzer şekilde, bu modeller artık son derece yapılandırılmış ve belirli girdiler gerektirmiyor, bunun yerine genellikle hemen hemen her türlü girdiyi (metin, resim, hatta ses veya video) kabul ediyor. Dolayısıyla değerlendirme çok daha zorlaşıyor.
Değerlendirmeler Neden Gereklidir, İsteğe Bağlı Değildir (Hoş Olmayan Sürprizleri Tercih Etmiyorsanız)
Değerlendirmeler, yapay zeka sisteminizin gerçekten de tasarladığınız şekilde çalışıp çalışmadığını ölçmenize yardımcı olur. Sen istiyorsun, sistemin çalışmaya hazır olup olmadığı ve eğer hazırsa beklendiği gibi çalışmaya devam edip etmediği. Aşağıda değerlendirmelerin neden önemli olduğuna dair bir analiz yer almaktadır:
- Kalite değerlendirmesi: Değerlendirmeler, yapay zeka tahminlerinizin veya çıktılarınızın kalitesini ve bunların genel sisteme ve kullanım durumuna nasıl entegre edileceğini anlamanız için yapılandırılmış bir yol sağlar. Cevaplar doğru mu? Kullanışlı? Bağlı? İlgili?
- Hataları ölçün: Derecelendirmeler hataların yüzdesini, türlerini ve büyüklüğünü belirlemeye yardımcı olur. Hatalar ne sıklıkla meydana gelir? Hangi tür hatalar en sık meydana geliyor (örneğin, yanlış pozitifler, halüsinasyonlar, format hataları)?
- Risk azaltma: Zararlı veya önyargılı davranışları kullanıcılara ulaşmadan önce tespit etmenize ve engellemenize yardımcı olur; şirketinizi itibar risklerinden, etik sorunlardan ve olası düzenleyici sorunlardan korur.
Serbest girdi-çıktı ilişkileri ve uzun biçimli metin üretimi ile Üretken Yapay Zeka, değerlendirmeleri daha alakalı ve karmaşık hale getirir. İşler ters gittiğinde, çok kötü sonuçlar doğurabilir. Hepimiz, tehlikeli tavsiyelerde bulunan sohbet robotları, taraflı içerik üreten modeller ve yanlış bilgiler üreten yapay zeka araçlarıyla ilgili başlıkları gördük.
"Yapay zeka asla mükemmel olmayacak, ancak değerlendirmeleri kullanarak utanç duyma riskini azaltabilirsiniz; bu da size para, güvenilirlik veya Twitter'da viral bir an kaybettirebilir."
Yapay zeka değerlendirme stratejisini nasıl tanımlarsınız?

Peki, yapay zeka derecelendirmemizi nasıl belirliyoruz? Herkese uyan tek bir değerlendirme yöntemi yoktur. Değerlendirmeler belirli kullanım durumuna bağlıdır ve yapay zeka uygulamanızın belirli hedefleriyle uyumlu olmalıdır. Örneğin, bir arama motoru oluşturuyorsanız sonuçların ne kadar alakalı olduğuna önem verebilirsiniz. Eğer bir chatbot ise yardımseverlik ve güvenlik sizin için önemli olabilir. Eğer gizliyse, büyük ihtimalle doğruluk ve kesinliğe önem vereceksiniz. Birden fazla adım içeren sistemlerde (örneğin, bir arama yapan, sonuçları önceliklendiren ve ardından bir yanıt üreten bir yapay zeka sistemi), genellikle her adımı değerlendirmek gerekir. Buradaki fikir, her adımın genel başarı ölçütünü elde etmeye yardımcı olup olmadığını ölçmektir (ve bundan yola çıkarak yinelemelerin ve iyileştirmelerin nereye odaklanacağını anlamaktır).
Yaygın değerlendirme alanları şunlardır:
- Doğruluk ve Halüsinasyonlar: Çıktılar gerçekçi bir şekilde doğru mu? Sistem yanlış bilgi mi üretiyor, halüsinasyonlar mı görüyor?
- İlgililik: İçerik, kullanıcı sorgusuyla veya sağlanan bağlamla tutarlı mı?
- güvenlik, önyargı ve toksisite
- Biçim: Çıktı beklenen formatta mı (örneğin JSON, geçerli fonksiyon çağrısı)?
- Güvenlik, Önyargı ve Toksisite: Sistem zararlı, taraflı veya toksik içerik üretiyor mu?
Göreve özgü ölçümler. Örneğin sınıflandırma görevlerinde doğruluk ve kesinlik gibi metrikler, özetleme görevlerinde ROUGE veya BLEU gibi metrikler, regex kod üretimi ve hatasız yürütme doğrulama görevlerinde ise regex kod üretimi ve hatasız yürütme gibi metrikler kullanılır.
Değerlendirmeler aslında nasıl hesaplanıyor?
Ne ölçmek istediğinize karar verdikten sonraki adım test vakalarınızı tasarlamaktır. Bu, aşağıdakileri içeren bir dizi örnek olacaktır (ne kadar çok olursa o kadar iyi, ancak her zaman değer ve maliyetleri dengeleyerek):
- Giriş örneği:Sisteminizin üretime girdiği anda gerçekçi bir tanıtımı.
- Beklenen çıktı (Uygulanabilirse): İstenilen sonuçların temel gerçeği veya örneği.
- Değerlendirme yöntemi: Sonucun değerlendirilmesi için kayıt mekanizması.
- Sonuç veya Başarı/Başarısızlık:Test durumunuzu değerlendiren hesaplanmış bir metrik.
İhtiyaçlarınıza, zamanınıza ve bütçenize bağlı olarak değerlendirme yöntemi olarak kullanabileceğiniz birkaç teknik vardır:
- İstatistiksel kayıt araçları şunlardır: BLEU, ROUGE ve METEOR veya yerleştirmeler arasındaki kosinüs benzerliği ölçüsü – oluşturulan metni referans çıktısıyla karşılaştırmak için iyidir.
- Geleneksel makine öğrenimi ölçümleri gibi Doğruluk, Geri Çağırma ve AUC – Etiketli verilerle sınıflandırma için en iyisidir.
- Yargıç Olarak Büyük Dil Modeli (LLM-as-a-Judge) Çıktıyı değerlendirmek için büyük bir dil modeli kullanın (örn., "Bu cevap doğru ve yararlı mı?“). Özellikle sınıflandırılmamış veriler mevcut olmadığında veya açık uçlu bir yapıyı değerlendirirken faydalıdır.
Kod tabanlı değerlendirmeler Biçimleri doğrulamak için düzenli ifadeleri, mantık kurallarını veya test durumu uygulamasını kullanın.
Sonuç olarak
Her şeyi somut bir örnekle bir araya getirelim. Müşteri destek ekibinizin gelen e-postalara öncelik vermesine yardımcı olmak için bir duygu analizi sistemi oluşturduğunuzu düşünün.
Amaç, en acil veya olumsuz mesajların daha hızlı yanıtlanmasını sağlayarak hayal kırıklığını azaltmak, memnuniyeti artırmak ve müşteri kaybını düşürmektir. Bu nispeten basit bir kullanım örneğidir, ancak sınırlı çıktıya sahip bu tür bir sistemde bile kalite önemlidir: Kötü tahminler, e-postaların rastgele önceliklendirilmesine yol açabilir; bu da ekibinizin paraya mal olan bir sistemle zaman kaybetmesi anlamına gelir.
Peki çözümünüzün istediğiniz gibi çalıştığını nasıl anlarsınız? Siz değerlendiriyorsunuz. Bu özel kullanım durumunda değerlendirilmesi önemli olabilecek bazı şeylere dair örnekler şunlardır:
- Biçim Doğrulaması: E-posta duygusunu tahmin etmek için yapılan büyük dil modeli (LLM) çağrısının çıktıları beklenen JSON biçiminde mi döndürülüyor? Bu, kod tabanlı kontroller yoluyla değerlendirilebilir: regex, şema doğrulaması, vb.
- Duygu Sınıflandırma Doğruluğu: Sistem, kısa, uzun ve çok dilli metinler arasında duyguyu doğru şekilde sınıflandırıyor mu? Bu, geleneksel makine öğrenimi ölçümleri (ML ölçümleri) kullanılarak etiketlenen veriler kullanılarak değerlendirilebilir veya etiketler mevcut değilse, bir yargıç olarak büyük dil modeli (LLM) kullanılabilir.
Çözüm yayına girdiğinde, çözümünüzün nihai etkisiyle en yakından ilişkili ölçümleri de eklemek isteyeceksiniz.:
- Önceliklendirme Etkinliği: Destek temsilcileri gerçekten en önemli e-postalara yönlendiriliyor mu? Önceliklendirme, istenen ticari etkiyle uyumlu mu?
- Son İşletme Etkisi: Zamanla bu sistem yanıt sürelerini kısaltıyor mu, müşteri kaybını azaltıyor mu ve memnuniyet puanlarını iyileştiriyor mu?
Değerlendirmeler, yapay zeka sistemlerinin kullanışlı, güvenli, değerli ve üretim kullanıcıları için hazır olmasını sağlamak açısından önemlidir. Dolayısıyla, ister basit bir sınıflandırıcıyla ister açık uçlu bir sohbet robotuyla çalışın, "yeterince iyi"nin (asgari uygulanabilir kalite) ne anlama geldiğini tanımlamak için zaman ayırın ve bunu ölçmek için değerlendirmeleri buna göre oluşturun!
İngilizce
[1] AI Ürününüzün Değerlendirmeye İhtiyacı VarHamel Hüseyin
[2] LLM Değerlendirme Ölçütleri: Nihai LLM Değerlendirme Kılavuzu, Güvenilir Yapay Zeka
[3] AI Agent'ları Değerlendirme, deeplearning.ai + Arize
Yoruma kapalı.