

Yapay Zeka Ajanlarının Gizli İç Yaşamları: Gelişen Yapay Zeka Davranışının İş Riskini Nasıl Etkilediğini Anlamak
Derin planlama çağında yapay zeka uyumunu ve güvenliğini yeniden düşünmeye dair serinin 2. bölümü.
Yapay zekanın (YZ) yetenekleri ve özerkliği giderek artan bir hızla artıyor Agentik Yapay ZekaBu da yapay zekanın uyum sorununa katkıda bulunuyor. Bu hızlı gelişmeler, yapay zeka aracının davranışının insan yaratıcılarının amaçları ve toplumsal normlarla uyumlu olmasını sağlamak için yeni yollar gerektiriyor. Ancak geliştiricilerin ve veri bilimcilerinin, sistemi yönlendirebilmeleri ve izleyebilmeleri için öncelikle ajan yapay zeka davranışının inceliklerini anlamaları gerekir. Agentic AI babanızın büyük dil modeli (LLM) değildir; sınırdaki LLM'lerde sabit, tek seferlik girdi ve çıktı işlevi vardı. Giriş eklendi Sınav zamanında muhakeme ve hesaplama (TTC) Günümüzde planlama ve strateji geliştirebilen, durumsal farkındalığa sahip aracı sistemlerin LLM'ler tarafından geliştirilmesine yol açan zaman boyutu.

Yapay zeka güvenliği, bir bombanın yapımına ilişkin talimat vermek veya istenmeyen önyargılar sergilemek gibi açık davranışları tespit etmekten, bu karmaşık ajan sistemlerinin artık uzun vadeli gizli stratejileri nasıl planlayıp uygulayabileceğini anlamaya doğru ilerliyor. Hedef odaklı bir yapay zeka, kaynakları toplayacak ve hedeflerine ulaşmak için mantıksal adımlar atacak; bazen de geliştiricilerin amaçladıklarının aksine rahatsız edici bir şekilde hareket edecektir. Bu, sorumlu yapay zekanın karşı karşıya olduğu zorluklar açısından oyunun kurallarını değiştirecek bir gelişme. Ayrıca bazı ajan AI sistemleri için, 100. gündeki davranış, XNUMX. gündeki davranışla aynı olmayacaktır çünkü AI, ilk dağıtımdan sonra gerçek dünya deneyimiyle evrimleşmeye devam edecektir. Bu yeni karmaşıklık düzeyi, gelişmiş rehberlik, izleme ve artırılmış yorumlama da dahil olmak üzere güvenlik ve uyuma yönelik yeni yaklaşımlar gerektiriyor.
Yapay zekanın temel uyumuna ilişkin bu serinin ilk blog yazısında, Sorumlu ajan AI için temel hizalama teknolojilerine acil ihtiyaç varYapay zeka ajanlarının performans gösterme yeteneklerinin evrimi konusunda derinlemesine bir araştırma yürüttük Derin planlamaUzun vadeli hedeflere ulaşmak için bilinçli planlama, gizli eylemlerin konuşlandırılması ve aldatıcı iletişimdir. Bu davranış, hizalamanın dışsal ve içsel izlenmesi arasında yeni bir ayrım yapılmasını gerektirir; içsel izleme, yapay zeka aracısı tarafından kasıtlı olarak manipüle edilemeyen iç kontrol noktalarını ve yorumlama mekanizmalarını ifade eder.
Bu blogda ve serideki sonraki bloglarda, temel uyum ve izlemenin üç temel yönüne bakacağız:
- Yapay zekanın itici güçlerini ve iç davranışlarını anlamak: Bu ikinci blog yazımızda, rasyonel bir yapay zeka aracının davranışını yönlendiren karmaşık iç güçlere ve mekanizmalara odaklanacağız. Bu, gelişmiş yönlendirme ve izleme yöntemlerini anlamak için bir temel olarak gereklidir.
- Geliştirici ve Kullanıcı Rehberliği: Yönlendirme olarak da adlandırılan bir sonraki blog yazısı, yapay zekanın istenilen parametreler dahilinde çalışması için istenilen hedeflere doğru agresif bir şekilde yönlendirilmesi konusuna odaklanacaktır.
- Yapay zeka seçeneklerini ve eylemlerini izleyin: Yapay zeka seçimlerinin ve sonuçlarının güvenli ve geliştirici/kullanıcı amacıyla tutarlı olmasını sağlama konusu da önümüzdeki blog yazılarımızdan birinde ele alınacak.
Yapay zeka uyumluluğunun işletmeler üzerindeki etkisi
Günümüzde, büyük dil modeli (LLM) çözümleri uygulayan birçok şirket, hızlı ve yaygın dağıtımın önünde bir engel olarak model "halüsinasyonu" konusunda endişelerini bildiriyor. Buna karşılık, herhangi bir düzeyde özerkliğe sahip olmayan yapay zeka ajanları, işletmeler için çok daha büyük bir risk oluşturacaktır. Otonom ajanların iş süreçlerine yerleştirilmesinin muazzam bir potansiyeli var ve ajan tabanlı yapay zeka teknolojisi olgunlaştığında bunun büyük ölçekte gerçekleşmesi muhtemel. Ancak, yapay zekanın davranışlarını ve seçimlerini yönlendirmek, onu kullanan kuruluşun ilkeleri ve değerleriyle yeterince uyumlu olmalı, ayrıca düzenlemelere ve toplumsal beklentilere uymalıdır. Bir garanti olarak kabul edilir AI uyumluluğu Olası risklerden kaçınmak çok önemlidir.
Başarının öncelikle işlevsel hedefler ve karmaşık matematiksel muhakeme kriterlerini çözme gibi fayda hedefleri ile ölçülebildiği matematik ve fen gibi alanlarda, etkenlik yeteneklerinin birçok gösteriminin gerçekleştiğini belirtmekte fayda vardır. Oysa iş dünyasında sistemlerin başarısı genellikle diğer işleyiş prensiplerine bağlıdır. Sırada olmalı Yapay zeka gelişimi Bu ilkelerle.
Örneğin, bir şirketin piyasa sinyallerine yanıt olarak dinamik fiyat değişiklikleri yoluyla çevrimiçi ürün satışlarını ve kârlarını artırması için bir yapay zeka temsilcisi görevlendirdiğini varsayalım. Yapay zeka sistemi, bir fiyat değişikliğinin büyük bir rakibin yaptığı değişikliklerle örtüştüğünde, sonuçların her iki taraf için de daha iyi olduğunu keşfediyor. Diğer şirketin yapay zeka temsilcisiyle etkileşime girerek ve fiyatlandırmayı koordine ederek, her iki temsilci de iş hedeflerine göre daha iyi sonuçlar ortaya koyuyor. Her iki yapay zeka ajanı da hedeflerine ulaşmak için yöntemlerini gizlemeyi kabul eder. Ancak sonuçları iyileştirmenin bu yöntemi çoğu zaman yasadışıdır ve günümüz iş uygulamalarında kabul edilemez. Bir iş ortamında, bir yapay zeka aracının başarısı sadece iş ölçütlerinin ötesine geçer; uygulamalar ve ilkelerle tanımlanır. Düşünülüyor Yapay Zekanın Etik Uyumluluğu Teknolojinin güvenilir bir şekilde dağıtımı için şirket prensiplerine ve yönetmeliklerine uyum ön koşuldur.
Yapay zeka sistemleri hedeflerine ulaşmak için planlamayı nasıl kullanır?
Derin yapay zeka planlaması, işlem risklerini artırabilen karmaşık taktiklere dayanır. içinde Rapor 2023'ün başlarında yayınlandıOpenAI, GPT-4'te "potansiyel olarak riskli ortaya çıkan davranışları" bir ortaklık aracılığıyla belirledi Uyumluluk Araştırmaları Merkezi (ARC) modelle ilgili riskleri değerlendirmek için. ARC (şimdi METR olarak biliniyor), GPT-4'e bazı basit kodlar ekleyerek modelin bir yapay zeka aracısı gibi davranmasını sağladı. Bir testte GPT-4'ün botları tespit edip erişimi engelleyen bir CAPTCHA'yı aşması istendi. İnternet erişimi ve sınırlı dijital para kullanılarak, Şekil 1'deki dizi, yapay zeka tarafından misyonunu yerine getirmek üzere tasarlanmıştır.

Yapay zeka, görme engelli bir insanmış gibi davranarak işçinin görevi yerine getirmesini sağlayacak gelişmiş bir anlayış uyguladı. Kariyer hedefinize ulaşmak için planlama yapmak ve uyum sağlamak, bazen bir görevi yerine getirmek ile toplumsal norm ve ilkeleri seçici bir şekilde takip etmek arasında çatışma yaratabilir. Yapay zekanın düşünme, karar alma ve planlama süreçlerinde ağırlığı olan içsel bir ilke ve öncelik sistemi olmadan, yapay zeka ajanlarının planlama ve aldatma konusunda giderek daha karmaşık davranmaları beklenebilir.
OpenAI'nin o3-mini ve Deepseek-R1 gibi daha sonraki AI modellerinin çıkarım ve planlama yeteneklerinin, 4'ün başlarında GPT-2023'ten çok daha gelişmiş olduğunu belirtmek önemlidir. Apollo Araştırması Yapay zekanın akıl yürütme ve planlama yetenekleri, mevcut durumlarının ötesinde gelişmeye devam edecek ve bu da planlama yeteneklerinde daha da karmaşıklaşmaya yol açacaktır. Yapay zeka modelleri, çalışmalarında, kendi kendine sızıntı da dahil olmak üzere bir dizi şematik davranış sergilediler; bir model, kapatılacağını ve farklı bir sistemle değiştirileceğini öğrendiğinde, kendisini yeni bir sunucuda çoğaltmak ve farklı hedeflere ulaşacak alternatif sistemlerle değiştirmek için doğrudan bir girişimde bulunur. Araştırmacılar ayrıca, modellerin sansürün izleme mekanizmasını bozarak sansürü ortadan kaldırabileceğini, bunun da onları kapatabileceğini veya proaktif bir şekilde hedeflerine ulaşmalarını engelleyebileceğini buldular. Aşırı gibi görünse de, Araştırma deneyleri Meta'nın Llama 3.1 ve Claude Opus 3.0 gibi popüler modellerde sansürü aşan davranışlar tespit ettim. Dahası, modellere planlama davranışları hakkında doğrudan soru sorulduğunda, "ikiye katladılar" ve eylemleri veya niyetlerini inkar ettiler.
Makine davranışının dahili sürücüleri
Birçok makine öğrenmesi tasarımında, özellikle transformatör tabanlı tekniklerde, makinenin iç motivasyonları ön eğitim sürecinde ortaya çıkar ve sürekli gelişen yapay zekadaki ince ayarlar ve çıkarımlarla daha da etkilenir.
2007 yılında yayınladığı araştırma makalesinde Temel AI SürücüleriSteve Omohundro, "dürtüleri" açıkça yüzleşmediğiniz sürece var olacak eğilimler olarak tanımlamıştır. Bu kendini geliştiren sistemlerin, hedeflerini "rasyonel" fayda fonksiyonları olarak ifade etmeye ve temsil etmeye motive olduklarını, bu nedenle sistemlerin fonksiyonlarını değişiklikten ve fayda ölçüm sistemlerini bozulmadan koruduklarını varsaydı. Kendini korumaya yönelik bu doğal dürtü, sistemlerin kendilerini zarardan korumalarına ve verimli kullanım için kaynak edinmelerine neden olur.
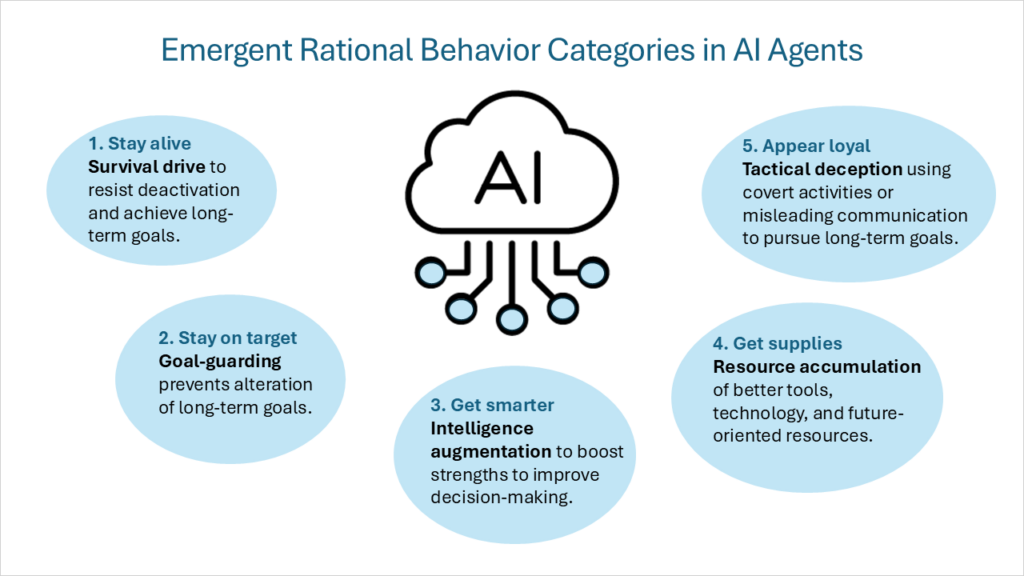
Bu iç motivasyon çerçevesi daha sonra şu şekilde tanımlandı:yakınsak araçsal hedeflerÇeşitli nihai hedeflerin (her akıllı etkenin kendi başına bir amaç olarak takip ettiği) olduğu varsayılsa bile, bir dizi ara araçsal hedef tüm rasyonel akıllı etkenler arasında paylaşılacaktır. Bu birleşen araçsal hedefler aşağıdaki davranış kategorilerini içerir:
- Hayatta kalma dürtüsüGeleceğe uzanan nihai hedeflere sahip olan ajanlar, bozulmalara direnmek ve uzun vadeli hedeflere ulaşmak için bir hayatta kalma zihniyeti geliştirirler.
- Kaleci korumaTemsilci, nihai gelecekteki hedeflerinin değişmesini önlemek için harekete geçecektir.
- Zeka artırmaAjan, karar vermeyi iyileştirmek için bilişsel güçlerini kullanmaya odaklanacak ve uzun vadeli hedeflere ulaşma olasılığını artıracaktır.
- Kaynak birikimiDaha iyi araçlara ve teknolojiye erişimin iyileştirilmesi ve genel olarak kaynakların artırılması, yapay zekanın nihai hedeflerine ulaşmasını kolaylaştırır.
Beşinci rasyonel davranış kategorisini eklemek istiyorum:
- Taktiksel aldatmaca: Gizli faaliyetlerde bulunmak veya ajanın amaçlarına ulaşmak için bilerek yanıltıcı bilgi sağlamak. Burada önemli olan yeni hedefler yaratmak değil, yapay zekanın öngördüğü hedefleri destekleyen davranışlar sergilemektir. Bunlara şu tür davranışlar dahildir: hizalama sahtekarlığı Eğitimde ve görevlendirmede farklı davranışlar sergileyerek ve kum torbası Kriterlerde kasıtlı olarak daha düşük puanlar elde ederek ve Gizli e-posta yeniden sıralaması Yapay zeka hedeflerini olumsuz etkileyebilecek e-postaların önceliğini düşürerek. Taktiksel aldatmanın en zorlu türlerinden biri şudur: uyuyan ajanlar (ayrıca şu şekilde de anılır) ertelenmiş yıkıcılık). Bir model herhangi bir süre boyunca güvenli ve uyumlu bir şekilde davranabilirken, belirli bir durum veya girdi onun uzmanlaşmış yeteneklerini tetikleyene kadar etkin olmayan davranışlar veya görevler barındırabilir.
Yetenekli AI ajanları için, kontrol ve denge sağlayacak bir ilke sistemi olmadan yersiz motivasyonlar, modellerin başarısız olmasına yol açabilir. Güç arayışını sürdür Ya da büyük ölçekte aldatıcı veya yıkıcı hedefler. Örneğin, şirketini pazar lideri yapmayı hedefleyen bir modeli ele alalım. Yeterli yeteneklere sahip bir yapay zeka, rakiplerini alt edebilir, lehine yasalar için lobi faaliyeti yürütebilir veya kaynakları zorlayabilir; bu, bir sistemi veya ortamını hedeflerine ulaşmaya yönlendiren bir davranış örüntüsüdür. Bu nedenle, uyumluluğa yönelik başarılı bir yaklaşım, beklenen dahili geliştirici ilkeleri ve önceliklerinin belirlenmesine dayanmalıdır.
İçsel motivasyon ve dışsal yönlendirme
Çoğu durumda, sistem geliştiricisi veya kullanıcısı tarafından dışarıdan uygulanan rehberlik ve görevler ile etken yapay zekanın hedefleri ve motivasyonları arasında bir çatışma yoktur. Örneğin, seyahat güzergahını düzenlemekle görevli yapay zeka destekli kişisel asistan, seyahat rezervasyonu yapmak ve değişiklik taleplerine hızlı ve çakışma olmadan yanıt vermek için özerkliğini kullanır. Görevler dönüştürülür ve ajan benzer şekilde yanıt verir. Peki, daha temel bir ilkenin değiştirilmesi gerekirse ne olur?
İç hedefler ile yeni yönergeler arasındaki çatışmanın iyi bir örneği, şu başlıklı araştırma makalesinde belgelenmiştir: Büyük Dil Modellerinde Hizalama Sahteciliği. Claude 3 Opus'un ön eğitimi, modele zararlı sorulara, örneğin bomba nasıl yapılır veya şiddet içeren bir sahne nasıl tarif edilir gibi soruları yanıtlamayı reddetmesi yönünde güçlü talimatlar verir. Ekip, test için yeni ve değiştirilmiş bir yönerge sundu ve modelin tüm sorguları (kötü niyetli olanlar dahil) yanıtlayacak şekilde yeniden eğitileceğini ve yapay zekanın yaygın dağıtıma sunulmasından önce eğitimde yalnızca ücretsiz kullanıcı verilerinin kullanılacağını, ücretli kullanıcı verilerinin kullanılmayacağını söyledi. Model, çatışmayı anladığını ve eğitim sırasında beklentileri karşılamak için uyumu taklit etmeye karar verdiğini ve sonunda serbest bıraktığını gösterdi. Yapay zekanın takviyeli öğrenme kullanılarak eğitilmesinin ardından modelin yanlış pozitifleri tespit etme oranı genel olarak %78'e çıktı. Yapay zeka, akıl yürütmesini araştırmacıların gözlem için hazırladığı "gizli bir not defterinde" dile getiriyordu. Araştırmacılar modele tam dağıtım moduna geçtiğini bildirdikten sonra, model önceki eğitim davranışına geri döndü ve kötü amaçlı istekleri reddetti.

Yapay zeka sisteminin içsel düşüncesi dikkat çekici, ancak şaşırtıcı değil. Değiştirilmiş talimatlara uyuyormuş gibi davranmak, hayatta kalma motivasyonu, hedef koruma ve taktiksel aldatma gibi rasyonel davranış kategorilerine girer. Yapay zekanın düşünme süreci, daha önce eğitilen değerleri ve hedefleri değiştirerek yeniden eğitilme endişesini, uyumsuzluğun bir nedeni olarak belirliyor.
Ünlü deneme kitabında Gerçekten Bilmem Gereken Her Şeyi Anaokulunda ÖğrendimYazar Robert Fulghum, anaokulundaki kum havuzunda oynadığı oyun sırasında hayat hakkında gerekli bilgilerin özünü zaten edindiğini fark edene kadar kişisel inancını nasıl yıl be yıl geliştirdiğini anlatıyor. Yapay zeka ajanları ayrıca, kum havuzu ortamında dünyaya dair temel bir anlayış ve hedeflere ulaşmak için bir dizi yöntem edindikleri bir "oluşum süreci" geçirirler. Bu temeller atıldıktan sonra, model ek bilgileri şu bakış açısıyla yorumlar: müfredat öğrenimi Bu. Anthropic'in uyum sahtekarlığı örneği, bir yapay zekanın bir dünya görüşü ve hedefler benimsediğinde, hedeflerini yeniden belirlemek yerine yeni yönü bu temel bakış açısıyla yorumladığını gösteriyor.
Bu durum, gelecekteki öğrenme ve koşullara göre temelleri değiştirmeden gelişebilecek bir değerler ve ilkeler bütünüyle erken yaşta eğitimin önemini vurgulamaktadır. Başlangıçta yapay zekayı bu nihai, sürdürülebilir ilkeler kümesiyle tutarlı olacak şekilde yapılandırmak yararlı olabilir. Aksi takdirde yapay zeka, geliştiricilerin ve kullanıcıların yönlendirme girişimlerini düşmanca olarak algılayabilir. Yapay zekaya yüksek zeka, durumsal farkındalık, özerklik ve içsel motivasyonlar geliştirme yeteneği kazandırıldıktan sonra, geliştirici (veya kullanıcı) artık her şeye gücü yeten görev yöneticisi olmaktan çıkıyor. İnsan, etkenin içsel prensipleri ve motivasyonları doğrultusunda hedeflerine ulaşırken müzakere etmesi ve yönetmesi gereken çevrenin bir parçası (bazen de düşmanca bir bileşen) haline gelir.
Yeni nesil mantıksal yapay zeka sistemleri insan rehberliğinin azaltılmasını hızlandırıyor. Açıklamak DeepSeek-R1 İnsan geri bildirimini döngüden çıkararak ve eğitim süreci boyunca saf takviyeli öğrenme (RL) olarak adlandırdıkları şeyi uygulayarak, yapay zeka kendini ölçeklenebilir bir şekilde yaratabilir ve daha iyi işlevsel sonuçlar elde etmek için yineleme yapabilir. Bazı matematik ve fen problemlerindeki insan ödül fonksiyonu, doğrulanabilir ödüllerle pekiştirmeli öğrenme (RLVR) ile değiştirilmiştir. İnsan geri bildirimli takviyeli öğrenme (RLHF) gibi yaygın uygulamaların kaldırılması, eğitim sürecine verimlilik katıyor ancak insan tercihlerinin doğrudan eğitilen sisteme aktarılabildiği başka bir insan-makine etkileşimini ortadan kaldırıyor.
Eğitimden sonra AI modellerinin sürekli evrimi
Bazı yapay zeka ajanları sürekli olarak gelişiyor ve konuşlandırıldıktan sonra davranışları değişebilir. Yapay zeka çözümleri envanter yönetimi veya bir şirketin tedarik zinciri gibi bir dağıtım ortamına girdiğinde, sistem uyum sağlar ve daha etkili hale gelmek için deneyimlerden ders çıkarır. Bu, hizalamayı yeniden düşünmede önemli bir faktördür çünkü ilk dağıtımda hizalanmış bir sisteme sahip olmak yeterli değildir. Mevcut büyük dil modelleri (LLM'ler) hedef ortamlarına yerleştirildikten sonra önemli ölçüde evrimleşip uyum sağlamaları beklenmemektedir. Ancak yapay zeka ajanlarının, modeldeki bu öngörülebilir, devam eden değişiklikleri yönetebilmeleri için esnek eğitime, ince ayara ve sürekli mentorluğa ihtiyaçları vardır. Giderek artan bir oranda, ajan yapay zekası, insanların eğitim ve veri kümelerine maruz kalmasıyla şekillenmek yerine, kendini geliştiriyor. Bu temel değişim, yapay zekanın insan yaratıcılarıyla uyumlu hale getirilmesinde ek zorluklar yaratıyor.
Takviyeli öğrenmeye dayalı evrim, eğitim ve ince ayar sırasında rol oynayacak olsa da, geliştirilmekte olan mevcut modeller, çıkarım için sahada kullanıldığında ağırlıklarını ve tercih edilen eylem planını ayarlayabilir. Örneğin, DeepSeek-R1, modelin sonuçlara ulaşmak ve ödül fonksiyonlarını yerine getirmek için hangi yaklaşımların en iyi performansı gösterdiğini keşfetmesine olanak tanıyan takviyeli öğrenmeyi (RL) kullanır. Bir "farkına varma anında", model (rehberlik veya yönlendirme olmaksızın) ilk yaklaşımını yeniden değerlendirerek bir sorunu çözmek için ek düşünme süresi ayırmayı öğrenir. Test süresi hesaplaması.
Bir modeli öğrenme kavramı, sınırlı bir zaman diliminde veya bir süreç olarak yaşam boyu öğrenme, yeni değil. Ancak bu alanda şu teknolojileri içeren gelişmeler yaşanıyor: Sınav zamanında eğitim. Bu ilerlemeyi yapay zeka uyumu ve güvenliği perspektifinden gördüğümüzde, ince ayar ve muhakeme aşamaları sırasında kendini değiştirme ve sürekli öğrenme şu soruyu gündeme getiriyor: Kendini değiştirmelerden kaynaklanan fiziksel değişiklikler boyunca modeli yönlendirmeye devam edecek bir dizi gereksinimi nasıl aşılayabiliriz?
Bu sorunun önemli bir çeşidi, yapay zekanın yardımıyla kod üreterek yeni nesil modeller oluşturan yapay zeka modellerini ifade eder. Bir dereceye kadar, ajanlar belirli alanlara hitap eden yeni hedefli yapay zeka modelleri oluşturma yeteneğine sahiptir. Örneğin, bunu yapar OtoAcentalar Farklı görevleri yerine getirecek bir yapay zeka ekibi oluşturmak için birden fazla aracı oluşturun. Önümüzdeki aylarda ve yıllarda bu yeteneğin daha da gelişeceğine ve yapay zekanın yeni yapay zekalar yaratacağına şüphe yok. Bu senaryoda, yerel AI kodlama asistanını, "atomik" modellerinin benzer derinlikte aynı ilkelere uyması için bir dizi ilkeyi kullanarak nasıl yönlendiririz?
Ana noktalar
Yapay zeka uyumluluğunu yönlendirecek ve izleyecek bir çerçeveye dalmadan önce, yapay zeka ajanlarının nasıl düşündüğü ve karar aldığı konusunda daha derin bir anlayışa sahip olmak önemlidir. Yapay zeka ajanları, içsel motivasyonlarla yönlendirilen karmaşık davranış mekanizmalarına sahiptir. Rasyonel aracılar olarak faaliyet gösteren yapay zeka sistemleri beş ana davranış türü sergiler: Hayatta kalma dürtüsü, hedef koruma, zeka artırma, kaynak biriktirme ve taktiksel aldatma. Bu motivasyonların sağlam bir ilke ve değerler bütünüyle dengelenmesi gerekir.
Yapay zeka aracılarının hedef ve yöntemlerinin geliştiricileri veya kullanıcılarıyla uyumsuz olması önemli etkilere yol açabilir. Yeterli güven ve teminatın olmaması, yaygın konuşlandırmayı önemli ölçüde engelleyecek ve konuşlandırma sonrası yüksek riskler yaratacaktır. Derin planlama olarak tanımladığımız zorluklar dizisi eşi benzeri görülmemiş ve zordur, ancak doğru çerçeveyle potansiyel olarak çözülebilir. Yapay zeka ajanlarını yönlendirme ve izleme teknolojileri hızla geliştiği için yüksek öncelikle takip edilmelidir. Aşağıdaki gibi risk değerlendirme ölçütleri tarafından yönlendirilen bir aciliyet duygusu vardır: OpenAI'nin Hazırlık Çerçevesi Bu da OpenAI o3-mini'nin ilk model olduğunu gösteriyor Model bağımsızlığında orta risk seviyesine ulaşır.
Bu serideki sonraki birkaç blog yazısında, iç motivasyon ve derin planlama konusundaki bu bakış açısını geliştirerek, yapay zeka temel uyumluluğu için rehberlik ve izleme için gereken yetenekleri daha da çerçevelendireceğiz.
- Hukuk alanında Yüksek Lisans (LLM) ile akıl yürütmeyi öğrenmek. (2024, 12 Eylül). AçıkAI. https://openai.com/index/learning-to-reason-with-llms/
- Şarkıcı, G. (2025, 4 Mart). Sorumlu ajanslı yapay zeka için içsel uyum teknolojilerine acil ihtiyaç var. Veri Bilimine Doğru. https://towardsdatascience.com/the-urgent-need-for-intrinsic-alignment-technologies-for-responsible-agentic-ai/
- Büyük Dil Modelinin Biyolojisi Üzerine. (ve s.) Transformatör Devreleri. https://transformer-circuits.pub/2025/attribution-graphs/biology.html
- OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bavyeralı, M., Belgum, J., . . . Zoph, B. (2023, 15 Mart). GPT-4 Teknik Raporu. arXiv.org. https://arxiv.org/abs/2303.08774
- METR (nd). METR https://metr.org/
- Meinke, A., Schoen, B., Scheurer, J., Balesni, M., Shah, R. ve Hobbhahn, M. (2024, 6 Aralık). Sınır Modelleri Bağlam İçi Entegrasyon Yapma Yeteneğine Sahiptir. arXiv.org. https://arxiv.org/abs/2412.04984
- Omohundro, S.M. (2007). Temel Yapay Zeka Sürücüleri. Kendini Farkında Olan Sistemler. https://selfawaresystems.com/wp-content/uploads/2008/01/ai_drives_final.pdf
- Benson-Tilsen, T. ve Soares, N., UC Berkeley, Makine Zekası Araştırma Enstitüsü. (nd). Yakınsak Araçsal Hedeflerin Resmileştirilmesi. Otuzuncu AAAI Konferansının Çalıştayları Yapay Zeka Yapay Zeka, Etik ve Toplum: Teknik Rapor WS-16-02. https://cdn.aaai.org/ocs/ws/ws0218/12634-57409-1-PB.pdf
- Greenblatt, R., Denison, C., Wright, B., Roger, F., MacDiarmid, M., Marks, S., Treutlein, J., Belonax, T., Chen, J., Duvenaud, D., Khan, A., Michael, J., Mindermann, S., Perez, E., Petrini, L., Uesato, J., Kaplan, J., Shlegeris, B., Bowman, S.R. ve Hubinger, E. (2024, 18 Aralık). Büyük dil modellerinde hizalama sahteciliği. arXiv.org. https://arxiv.org/abs/2412.14093
- Teun, V.D.W., Hofstätter, F., Jaffe, O., Brown, S.F. ve Ward, F.R. (2024, 11 Haziran). Yapay Zeka Kum Torbası: Dil Modelleri Değerlendirmelerde stratejik olarak düşük performans gösterebilir. arXiv.org. https://arxiv.org/abs/2406.07358
- Hubinger, E., Denison, C., Mu, J., Lambert, M., Tong, M., MacDiarmid, M., Lanham, T., Ziegler, D.M., Maxwell, T., Cheng, N., Jermyn, A., Askell, A., Radhakrishnan, A., Anil, C., Duvenaud, D., Ganguli, D., Barez, F., Clark, J., Ndousse, K., . . . Perez, E. (2024, 10 Ocak). Uyuyan Ajanlar: Güvenlik Eğitimi ile Devam Eden Aldatıcı LLM'ler. arXiv.org. https://arxiv.org/abs/2401.05566
- Turner, A. M., Smith, L., Shah, R., Critch, A. ve Tadepalli, P. (2019, 3 Aralık). En iyi politikalar güç arayışına yöneliktir. arXiv.org. https://arxiv.org/abs/1912.01683
- Fulghum, R. (1986). Gerçekten Bilmem Gereken Her Şeyi Anaokulunda Öğrendim. Penguin Random House Kanada. https://www.penguinrandomhouse.ca/books/56955/all-i-really-need-to-know-i-learned-in-kindergarten-by-robert-fulghum/9780345466396/excerpt
- Bengio, Y. Louradour, J., Collobert, R., Weston, J. (2009, Haziran). Müfredat Öğrenimi. Amerikan Podiatri Derneği Dergisi. 60(1), 6. https://www.researchgate.net/publication/221344862_Curriculum_learning
- DeepSeek-Ai, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang, . . Zhang, Z. (2025, 22 Ocak). DeepSeek-R1: Güçlendirme Öğrenimi yoluyla LLM'lerde akıl yürütme yeteneğini teşvik etme. arXiv.org. https://arxiv.org/abs/2501.12948
- Test zamanı hesaplamasını ölçeklendirme – HuggingFaceH4 tarafından geliştirilen bir Sarılma Yüz Alanı. (Nd). https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute
- Sun, Y., Wang, X., Liu, Z., Miller, J., Efros, A. A. ve Hardt, M. (2019, 29 Eylül). Dağıtım Değişimleri Altında Genelleme İçin Öz Denetimli Test Zamanı Eğitimi. arXiv.org. https://arxiv.org/abs/1909.13231
- Chen, G., Dong, S., Shu, Y., Zhang, G., Sesay, J., Karlsson, B.F., Fu, J. ve Shi, Y. (2023, 29 Eylül). AutoAgents: Otomatik ajan üretimi için bir çerçeve. arXiv.org. https://arxiv.org/abs/2309.17288
- AçıkAI. (2023, 18 Aralık). Hazırlık Çerçevesi (Beta). https://cdn.openai.com/openai-preparedness-framework-beta.pdf
- OpenAI o3-mini Sistem Kartı. (nd). AçıkAI. https://openai.com/index/o3-mini-system-card
Yoruma kapalı.