

Akıllı karar alma devrelerini kullanarak büyük dil modellerinde (LLM) kesinliğe ulaşmak
Belirsizlik teknolojide yeni bir şey değil; tüm modern sistemler, matematiksel olarak kanıtlanmış kontrol yapıları kullanarak belirsiz girdi ve çıktıların üstesinden gelir.
Yapay zeka ajanlarının vaadi dünyayı kasıp kavuruyor. Temsilciler etraflarındaki dünyayla etkileşime girebilir, makaleler yazabilir (ancak bu makaleyi değil), sizin adınıza eylemlerde bulunabilir ve genel olarak herhangi bir görevi otomatikleştirmenin zor kısmını kolay ve erişilebilir hale getirebilirler.
Acenteler operasyonların en zor kısımlarına odaklanır ve sorunları hızla çözer. Bazen çok hızlı – Eğer aracı tabanlı sürecinizde sonuca karar vermek için döngüde bir insana ihtiyaç varsa, insan inceleme aşaması süreçte bir darboğaz haline gelebilir.
Temsilci tabanlı bir sürecin örneği, müşteri telefon görüşmelerinin işlenmesi ve sınıflandırılmasıdır. Yüzde 99.95 doğruluk oranına sahip bir müşteri temsilcisi bile 5 çağrıyı dinlerken 10,000 hata yapacaktır. Bunu bilmesine rağmen acente size söyleyemez. herhangi 5 çağrıdan 10,000'i yanlış sınıflandırıldı.

“Hâkim Olarak LLM” tekniği, her girdiyi başka bir LLM sürecine aktararak girdiden gelen çıktının doğru olup olmadığını değerlendirdiğiniz bir tekniktir. Ancak bu da başka bir LLM süreci olduğundan yanlış da olabilir. Bu iki olasılık işlemi, gerçek pozitifler, yanlış negatifler, gerçek negatifler ve yanlış pozitiflerden oluşan bir karışıklık matrisi oluşturur.
Başka bir deyişle, bir LLM süreci tarafından doğru sınıflandırılan bir girdi, yargıcı LLM tarafından yanlış olarak değerlendirilebilir veya tam tersi olabilir.
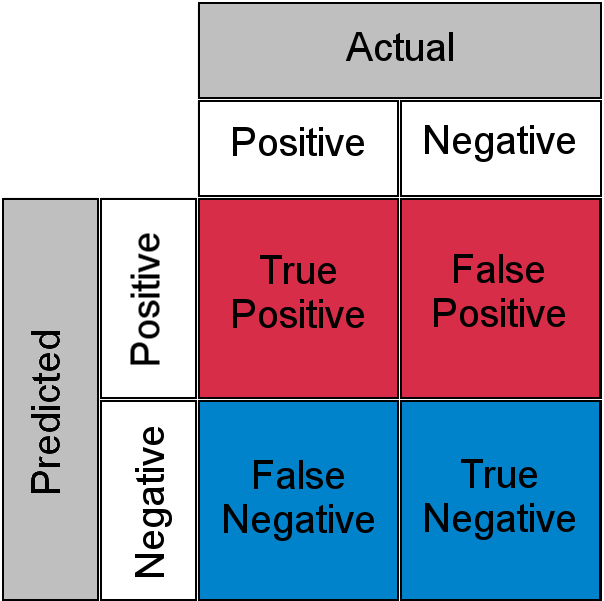
bu yüzden " Bilinmeyen bilinen "Hassas bir iş yükü için, bir insanın 10,000 çağrının hepsini incelemesi ve anlaması gerekir. Yine aynı darboğaz sorununa geri döndük.
Ajan odaklı süreçlerimize nasıl daha fazla istatistiksel kesinlik kazandırabiliriz? Bu yazıda, ajan odaklı süreçlerimizde daha emin olmamızı, bunu rastgele sayıda ajana genelleştirmemizi ve sisteme gelecekteki yatırımları yönlendirmeye yardımcı olacak bir maliyet fonksiyonu geliştirmemizi sağlayan bir sistem kuruyorum. Bu yazıda kullandığım kod, veri havuzumda mevcuttur. yapay zeka-karar-devreleri.
Yapay zeka karar alma devreleri
Hataları tespit etmek ve düzeltmek yeni bir kavram değildir. Dijital ve analog elektronik gibi alanlarda hata düzeltme hayati öneme sahiptir. Kuantum bilişimindeki ilerlemeler bile hata düzeltme ve tespit yeteneklerinin genişlemesine bağlıdır. Bu sistemlerden ilham alıp benzer bir şeyi yapay zeka ajanlarıyla hayata geçirebiliriz. Örneğin, şunları yapabilirsiniz: Yapay zeka algoritmaları İletişim sistemlerinde bulunan hata düzeltme tekniklerinin ileri düzeyde kullanımı.
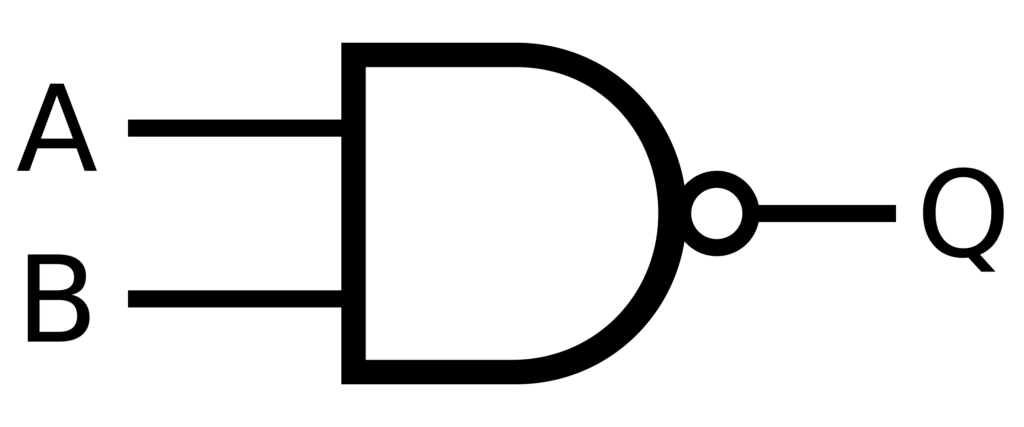
Boole mantığında, NAND kapıları hesaplamanın kutsal kasesidir çünkü her türlü işlemi gerçekleştirebilirler. İşlevsel olarak tamdır, yani herhangi bir mantıksal işlem yalnızca NAND kapıları kullanılarak oluşturulabilir. Bu ilke, yerleşik hata düzeltme özelliğine sahip sağlam karar alma yapıları oluşturmak için yapay zeka sistemlerine uygulanabilir. Bu, aşağıdakilerin oluşturulmasına olanak tanır: sinir ağları Daha güvenilir ve eksik veya gürültülü verileri işleyebilme.
Elektronik devrelerden akıllı karar alma (AI) devrelerine
Tıpkı elektronik devrelerin güvenilir hesaplamalar sağlamak için tekrarlama ve doğrulamayı kullanması gibi, akıllı karar alma (AI) devreleri de daha doğru sonuçlara ulaşmak için farklı bakış açılarına sahip birden fazla aracı kullanabilir. Bu devreler bilgi teorisi ve Boole mantığı prensipleri kullanılarak oluşturulabilir:
- Tekrarlanan İşleme: Birden fazla yapay zeka aracısı, modern CPU'ların donanım hatalarını tespit etmek için yedekli devreleri kullanmasına benzer şekilde, aynı girdileri bağımsız olarak işler. Bu işlem AI sisteminin güvenilirliğini artırır.
- Mutabakat Mekanizmaları: Karar çıktıları, hata toleranslı elektroniklerdeki çoğunluk mantık kapılarında olduğu gibi oylama sistemleri veya ağırlıklı ortalamalar kullanılarak birleştirilir. Bu mekanizmalar, nihai kararın aracılar arasındaki fikir birliğini yansıtmasını sağlar.
- Doğrulayıcı Aracılar: Uzman AI denetçileri, çıktıların makul olup olmadığını kontrol eder ve hata tespit kodlarına benzer şekilde çalışır. Eşlik bitleri أو döngüsel yedeklilik denetimleri (CRC denetimleri). Bu etkenler yanlış karar alma olasılığını azaltır.
- İnsan-Döngüde Entegrasyon: Biyometrik sistemlerin son doğrulama katmanı olarak insan denetimini kullanmasına benzer şekilde, karar alma sürecinin önemli noktalarında stratejik insan doğrulaması. Bu, önemli kararların insan değerlendirmesine tabi olmasını sağlar.
Yapay zekada karar alma devrelerinin matematiksel temelleri
Bu sistemlerin güvenilirliği olasılık teorisi kullanılarak nicel olarak belirlenebilir.
Bir faktör olarak, başarısızlık olasılığı, bir test veri kümesinde zaman içinde gözlemlenen doğruluktan gelir; bu veri kümesi, örneğin bir sistemde saklanır. LangSmith.

%90 doğruluk oranına sahip bir faktör için, arıza olasılığı, p_1، 1–0.9 0.1 yani %10.

Aynı girdide iki bağımsız faktörün başarısız olma olasılığı, her iki faktörün de doğru olma olasılığının birbiriyle çarpılmasıyla bulunur:
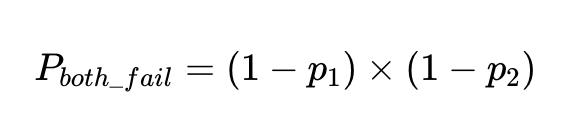
Bu istemcilerle N yürütmemiz varsa, toplam başarısızlık sayısı
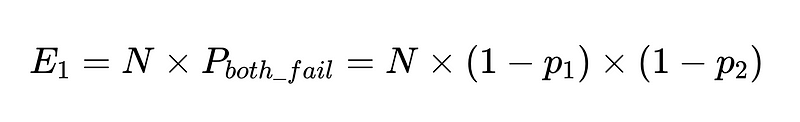
Yani iki bağımsız çalışan arasında %10,000 doğrulukla 90 yürütme için beklenen başarısızlık sayısı 100'dür.
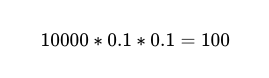
Ama bunu hâlâ bilmiyoruz. herhangi Bu 10,000 telefon görüşmesinin 100'ü gerçek başarısızlıkla sonuçlanıyor.
Herhangi bir yanıta güven sağlayan daha sağlam bir çözüm sağlamak için bu fikrin dört uzantısını birleştirebiliriz:
- Temel Sınıflandırıcı (Yukarıdaki Basit Çözüm)
- Yedekleme (yukarıdaki basit çözüm)
- Şema denetleyicisi (örneğin 0.7 çözünürlük)

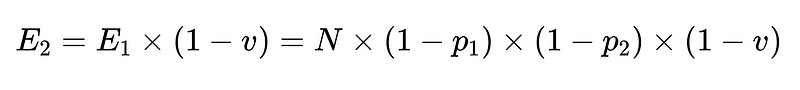
- Son olarak, negatif bir doğrulayıcı (örneğin n = doğruluk 0.6)
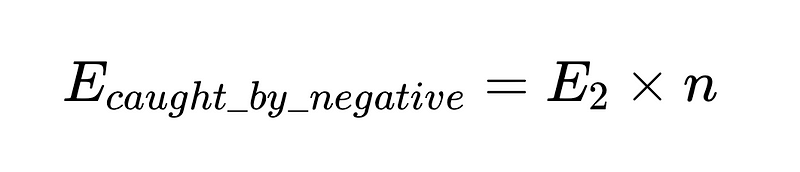
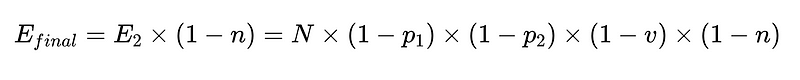
Bunu koda koymak için (Tam depo), kullanabiliriz Python temel:
def primary_parser(self, customer_input: str) -> Dict[str, str]:
"""
Primary parser: Direct command with format expectations.
"""
prompt = f"""
Extract the category of the customer service call from the following text as a JSON object with key 'call_type'.
The call type must be one of: {', '.join(self.call_types)}.
If the category cannot be determined, return {{'call_type': null}}.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def backup_parser(self, customer_input: str) -> Dict[str, str]:
"""
Backup parser: Chain of thought approach with formatting instructions.
"""
prompt = f"""
First, identify the main issue or concern in the customer's message.
Then, match it to one of the following categories: {', '.join(self.call_types)}.
Think through each category and determine which one best fits the customer's issue.
Return your answer as a JSON object with key 'call_type'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def negative_checker(self, customer_input: str) -> str:
"""
Negative checker: Determines if the text contains enough information to categorize.
"""
prompt = f"""
Does this customer service call contain enough information to categorize it into one of these types:
{', '.join(self.call_types)}?
Answer only 'yes' or 'no'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
answer = response.content.strip().lower()
if "yes" in answer:
return "yes"
elif "no" in answer:
return "no"
else:
# Default to yes if the answer is unclear
return "yes"
@staticmethod
def validate_call_type(parsed_output: Dict[str, Any]) -> bool:
"""
Schema validator: Checks if the output matches the expected schema.
"""
# Check if output matches expected schema
if not isinstance(parsed_output, dict) or 'call_type' not in parsed_output:
return False
# Verify the extracted call type is in our list of known types or null
call_type = parsed_output['call_type']
return call_type is None or call_type in CALL_TYPESBu işlemleri mantıkla birleştirerek, Boole Basitçe söylemek gerekirse, her cevapta benzer doğruluk ve güveni elde edebiliriz:
def combine_results(
primary_result: Dict[str, str],
backup_result: Dict[str, str],
negative_check: str,
validation_result: bool,
customer_input: str
) -> Dict[str, str]:
"""
Combiner: Combines the results from different strategies.
"""
# If validation failed, use backup
if not validation_result:
if RobustCallClassifier.validate_call_type(backup_result):
return backup_result
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If negative check says no call type can be determined but we extracted one, double-check
if negative_check == 'no' and primary_result['call_type'] is not None:
if backup_result['call_type'] is None:
return {'call_type': None, "confidence": "low", "needs_human": True}
elif backup_result['call_type'] == primary_result['call_type']:
# Both agree despite negative check, so go with it but mark low confidence
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If primary and backup agree, high confidence
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "high"}
# Default: use primary result with medium confidence
if primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {'call_type': None, "confidence": "low", "needs_human": True}
Karar Mantığı: Adım Adım Açıklama
Adım 1: Kalite kontrol sistemi başarısız olduğunda
if not validation_result:Bu şu anlama gelir: "Kalite kontrol uzmanımız (denetçimiz) ilk analizi reddederse, ona güvenmeyin." Sistem daha sonra yedek görüşü kullanmaya çalışır. Eğer bu da doğrulamadan geçemezse, vakayı bir insan uzmanının incelemesine sunar. Bu prosedür, yanlış verilere güvenmemenizi sağlar.
Basitçe söylemek gerekirse: "İlk cevabımızda bir sorun varsa, yedek yöntemimizi deneyelim. Bu hala şüpheliyse, bir insan uzmanından müdahale etmesini isteyelim." Bu sayede karmaşık vakaların doğru bir şekilde ele alınması sağlanır.
Adım 2: Uyuşmazlıkları giderin
if negative_check == 'no' and primary_result['call_type'] is not None:Bu adım, belirli bir tutarsızlık türünü kontrol eder: "Olumsuz denetleyicimiz bir çağrı türü olmaması gerektiğini gösteriyor, ancak temel analistimiz yine de bir tür buldu."
Bu gibi durumlarda sistem, zararı telafi etmek için yedek analiste güvenir:
- Eğer yedek analist çağrı tipinin olmadığı konusunda hemfikir olursa, çağrı insan unsuruna yönlendirilir.
- Eğer yedek analist birincil analistle aynı fikirdeyse, bu durumda kabul edilir, ancak orta düzeyde güvenle.
- Yedek analistin farklı bir çağrı türü varsa ← insan unsuruna gönderilir
Bu, "Bir uzman 'bu sınıflandırılamaz' derken diğeri 'sınıflandırılamaz' diyorsa, bir eşitliği bozan kişiye veya bir insan yargıca ihtiyacımız var" demeye benziyor. Bu mekanizma, çağrı tipi sınıflandırmasının doğru bir şekilde yapılabilmesi ve olası hataların azaltılması için gereklidir.
Adım 3: Uzmanlar anlaştığında
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:Hem birincil hem de yedek analistler bağımsız olarak aynı sonuca ulaştığında, sistem bunu “yüksek güvenilirlik” olarak işaretler; bu en iyi durum senaryosudur. Bu ideal durum, birden fazla analizin kesin olarak tutarlı olduğu durumlarda ortaya çıkar.
Basitçe söylemek gerekirse: "Farklı yöntemleri kullanan iki farklı uzman bağımsız olarak aynı sonuca ulaşırsa, onların sonucunun doğru olduğundan oldukça emin olabiliriz." Bu, doğruluk ve güvenilirliğin güçlü bir göstergesi olan uzmanların fikir birliğini temsil eder.
Adım 4: Varsayılan işleme
Özel koşulların hiçbiri geçerli değilse, sistem varsayılan olarak birincil analistin sonucuna "orta" güvenle döner. Birincil analist çağrının türünü belirleyemiyorsa, vakayı uzman bir insan analistin incelemesine sunar.
Hataları azaltmada bu yaklaşımın önemi
Bu mantık, şu şekilde güçlü bir sistem oluşturmaya katkıda bulunur:
- Yanlış pozitifleri azaltmaSistem, yalnızca birden fazla yöntem uyumlu olduğunda yüksek güvenirlik sağlıyor ve bu da yanlış alarmları büyük ölçüde azaltıyor.
- Çelişkileri keşfetmekSistemin farklı kısımları farklılık gösterdiğinde, bu durum ya güveni azaltır ya da konuyu insan değerlendiricilere taşır ve böylece hiçbir potansiyel sorunun gözden kaçırılmaması sağlanır.
- Akıllı tırmanmaİnsan değerlendiriciler yalnızca uzmanlıklarına gerçekten ihtiyaç duyulan vakaları görürler, bu da değerlendirme sürecinin verimliliğini artırır ve insan kaynakları stresini azaltır.
- Güven tanımıSonuçlar sistemin güven düzeyini içerir ve bu da sonraki süreçlerin yüksek güvenirlikli ve orta güvenirlikli sonuçları farklı şekilde ele almasına olanak tanır; bu da bilinçli kararlar almak için kritik öneme sahiptir.
Bu yaklaşım, elektronik aksamın sistem arızalarına yol açabilecek hataları önlemek için yedek devreler ve oylama mekanizmaları kullanmasına benzer. Yapay zeka sistemlerinde, bu tür dikkatli entegrasyon mantığı, insan değerlendiricileri yalnızca en fazla değer kattıkları yerlerde verimli bir şekilde kullanırken hata oranlarını önemli ölçüde azaltabilir. Bu sayede kaynakların optimize edilmesi ve hataların eş zamanlı olarak azaltılması sağlanarak daha güvenilir ve doğru bir sistem ortaya çıkar.
Misal
2015 yılında Philadelphia Şehri Su Dairesi şunları yayınladı: Kategoriye göre müşteri çağrı istatistikleri. Müşteri çağrılarını anlamak, temsilcilerin sıklıkla uğraştığı bir süreçtir. Her müşteri telefon görüşmesini bir insanın dinlemesi yerine, bir temsilci çağrıyı çok daha hızlı dinleyebilir, bilgi çıkarabilir ve daha fazla veri analizi için çağrıyı kategorilere ayırabilir. Su yönetimi açısından bu önemlidir, çünkü kritik sorunlar ne kadar erken tespit edilirse, bu sorunlar o kadar erken çözülebilir.
Bir deneyim inşa edebiliriz. Söz konusu telefon görüşmelerinin sahte dökümlerini oluşturmak için büyük dil modeli (LLM) kullandım ve şu soruyu sordum: "Aşağıdaki sınıf verildiğinde, bu telefon görüşmesinin kısa bir versiyonunu oluşturun: İşte tam dosyayla birlikte bu örneklerden bazıları. Burada:
{
"calls": [
{
"id": 5,
"type": "ABATEMENT",
"customer_input": "I need to report an abandoned property that has a major leak. Water is pouring out and flooding the sidewalk."
},
{
"id": 7,
"type": "AMR (METERING)",
"customer_input": "Can someone check my water meter? The digital display is completely blank and I can't read it."
},
{
"id": 15,
"type": "BTR/O (BAD TASTE & ODOR)",
"customer_input": "My tap water smells like rotten eggs. Is it safe to drink?"
}
]
}Şimdi, büyük bir dil modelini yargıç olarak kullanarak daha geleneksel bir değerlendirme ile deneyi kurabiliriz (Tam uygulama burada):
def classify(customer_input):
CALL_TYPES = [
"RESTORE", "ABATEMENT", "AMR (METERING)", "BILLING", "BPCS (BROKEN PIPE)", "BTR/O (BAD TASTE & ODOR)",
"C/I - DEP (CAVE IN/DEPRESSION)", "CEMENT", "CHOKED DRAIN", "CLAIMS", "COMPOST"
]
model = ChatAnthropic(model='claude-3-7-sonnet-latest')
prompt = f"""
You are a customer service AI for a water utility company. Classify the following customer input into one of these categories:
{', '.join(CALL_TYPES)}
Customer input: "{customer_input}"
Respond with just the category name, nothing else.
"""
# Get the response from Claude
response = model.invoke(prompt)
predicted_type = response.content.strip()
return predicted_typeSadece metni büyük dil modeline (LLM) geçirerek, döndürülen çıkarılan sınıftan gerçek sınıf bilgisini ayırabilir ve karşılaştırabiliriz.
def compare(customer_input, actual_type)
predicted_type = classify(customer_input)
result = {
"id": call["id"],
"customer_input": customer_input,
"actual_type": actual_type,
"predicted_type": predicted_type,
"correct": actual_type == predicted_type
}
return resultBunu Claude 3.7 Sonnet'i (bu yazının yazıldığı tarih itibarıyla en son model) kullanarak tüm sentetik veri kümesinde çalıştırmak, çağrıların %91'inin doğru şekilde sınıflandırılmasıyla çok yüksek bir performans sağlıyor:
"metrics": {
"overall_accuracy": 0.91,
"correct": 91,
"total": 100
}Bunlar gerçek çağrılar olsaydı ve kategori hakkında önceden hiçbir bilgimiz olmasaydı, yanlış sınıflandırılmış 100 çağrıyı bulmak için yine de tüm 9 telefon görüşmesini incelememiz gerekirdi.
Yukarıdaki güçlü karar alma devremizi uygulayarak, benzer doğruluk sonuçları elde ederiz. güven O cevaplarda. Bu durumda genel doğruluk %87 iken yüksek güvenilirlikli cevaplarımızda doğruluk %92.5'tir.
{
"metrics": {
"overall_accuracy": 0.87,
"correct": 87,
"total": 100
},
"confidence_metrics": {
"high": {
"count": 80,
"correct": 74,
"accuracy": 0.925
},
"medium": {
"count": 18,
"correct": 13,
"accuracy": 0.722
},
"low": {
"count": 2,
"correct": 0,
"accuracy": 0.0
}
}
}Yüksek güvenilirlikli cevaplarımızda %100 doğruluk oranına ihtiyacımız var, bu nedenle hâlâ yapılacak işler var. Bu yaklaşımın bize sağladığı şey, derinlemesine araştırma yapmaktır neden Yüksek güvenilirlikli cevapların yanlışlığı. Bu durumda zayıf iddialar ve basit doğrulama yetenekleri tüm konuları kapsamamakta ve sınıflandırma hatalarına yol açmaktadır. Bu yetenekler, yüksek güvenilirlikli cevaplarda %100 doğruluk elde etmek için yinelemeli olarak iyileştirilebilir.
Sonuçlara olan güveni artırmak için filtreleme sisteminde iyileştirmeler yapıldı.
Mevcut sistem, birincil ve yedek analistlerin hemfikir olması durumunda yanıtları “yüksek güvenilirlikli” olarak sınıflandırıyor. Daha yüksek doğruluk elde etmek için, "yüksek güven" olarak kabul edilen şey konusunda daha seçici olmalıyız.
# Modified high confidence logic
if (primary_result['call_type'] == backup_result['call_type'] and
primary_result['call_type'] is not None and
validation_result and
negative_check == 'yes' and
additional_validation_metrics > threshold):
return {'call_type': primary_result['call_type'], "confidence": "high"}Ek yeterlilik kriterleri ekleyerek daha az "yüksek güvenirlilik" sonucu elde edeceğiz, ancak bunlar daha doğru olacak. Filtreleme sisteminde yapılan bu iyileştirmeyle, yüksek kalitede sınıflandırılan verilerin güvenilirliğinin artırılması ve hataların azaltılması hedefleniyor.
Ek doğrulama teknikleri: Analizin doğruluğunu artırma
Veri doğrulama ve analiz sürecinizi geliştirmek için bazı fikirler şunlardır:
Üçüncül AnalizörÜçüncü bağımsız analiz yöntemini ekleyin. Bu yöntem, iki farklı analitik yöntemin sonuçlarını üçüncü bir yöntemin sonuçlarıyla karşılaştırarak daha fazla doğruluk sağlamak ve hata olasılığını azaltmak için ek bir doğrulama katmanı görevi görür.
# Only mark high confidence if all three agree
if primary_result['call_type'] == backup_result['call_type'] == tertiary_result['call_type']:Tarihsel Desen Eşleştirme:Sonuçları tarihsel olarak doğru sonuçlarla karşılaştırın (vektör aramasını düşünün). Bu teknikte referans olarak güvenilir tarihsel veriler kullanılır ve güncel sonuçlar bunlarla karşılaştırılarak herhangi bir sapma veya tutarsızlık tespit edilir. Analiz için bir tür "hafıza" olarak düşünülebilir, anormallikleri veya beklenmeyen durumları tespit etmeye yardımcı olur.
if similarity_to_known_correct_cases(primary_result) > 0.95:Karşıt TestGirdi değerlerine küçük değişiklikler uygulayarak sınıflandırmanın stabil kalıp kalmadığını kontrol edin. Bu yöntem, bir sınıflandırma sisteminin sağlamlığını ve güvenilirliğini, onu verilerdeki küçük değişikliklere maruz bırakarak test etmeyi amaçlamaktadır. Sistem bu değişikliklere karşı çok hassas ise, potansiyel zayıflıklar veya önyargılar ortaya çıkabilir.
variations = generate_input_variations(customer_input)
if all(analyze_call_type(var) == primary_result['call_type'] for var in variations):
Bir LLM çıkarma sisteminde insan müdahaleleri için genel formül
Tam özeti burada bulabilirsiniz..
- N = Toplam yürütme sayısı (örneğimizde 10,000)
- p_1 = temel ayrıştırıcının doğruluğu (örneğimizde 0.8)
- p_2 = geri dönüş ayrıştırıcısının doğruluğu (örneğimizde 0.8)
- v = şema doğrulayıcı etkinliği (örneğimizde 0.7)
- n = negatif denetleyicinin etkinliği (örneğimizde 0.6)
- H = gerekli insan müdahalelerinin sayısı
- E_final = son tespit edilemeyen hatalar
- m = bağımsız denetçi sayısı
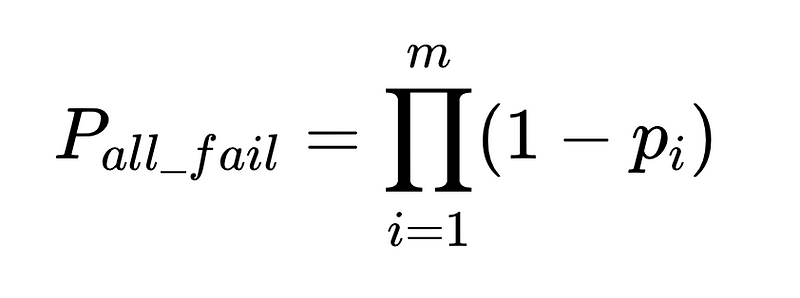
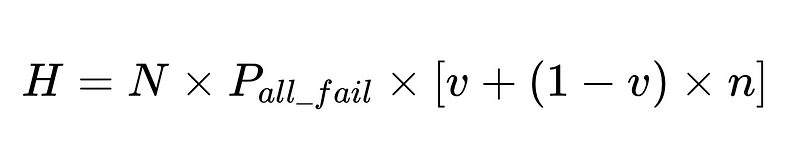
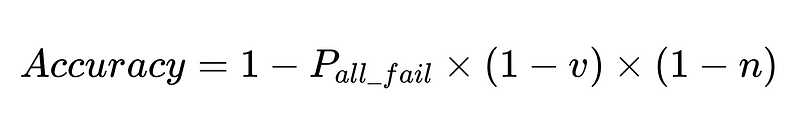
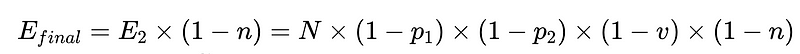
Optimum sistem tasarımı
Denklem, doğal dil işleme (NLP) sisteminin doğruluğuna ilişkin temel bilgileri ortaya koyuyor:
- Ayrıştırıcıların eklenmesi yükü azaltır ancak genel doğruluğu artırır.
- Sistem doğruluğu şunlarla sınırlıdır:
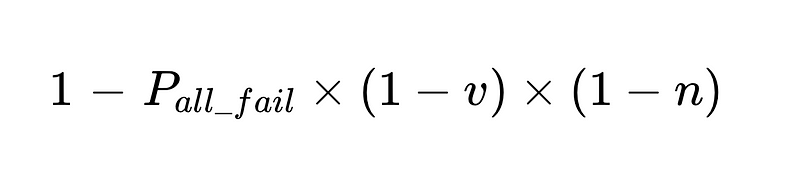
- İnsan müdahaleleri orantılıdır Doğrudan Toplam N infaz.
örnek:
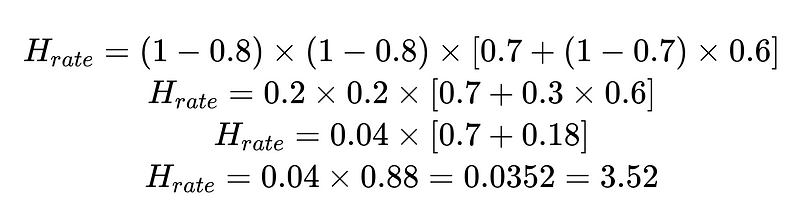
Çözümümüzün etkinliğini gerçek zamanlı olarak takip etmek için hesaplanan insan müdahale oranını (H_rate) kullanabiliriz. İnsan müdahalesi oranı %3.5'un üzerine çıkmaya başlarsa sistemin başarısız olduğunu anlarız. İnsan müdahalesi oranı sürekli olarak %3.5'in altına düşüyorsa, optimizasyonlarımızın beklendiği gibi çalıştığını biliyoruz.
maliyet fonksiyonu
Sistemimizi iyileştirmemize yardımcı olacak bir maliyet fonksiyonu da oluşturabiliriz. Maliyet fonksiyonu, bir sistemin finansal performansını değerlendirmek ve iyileştirmeye açık alanları belirlemek için güçlü bir analitik araçtır.
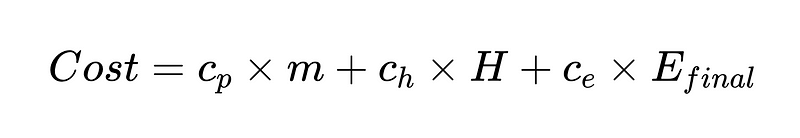
Nerede:
- c_p = ayrıştırıcı başına çalışma maliyeti (örneğimizde 0.10 ABD doları)
- m = ayrıştırıcının yürütüldüğü zaman sayısı (örneğimizde 2 * N)
- H = İnsan müdahalesi gerektiren vaka sayısı (Örneğimizden 352)
- c_h = bir insan müdahalesinin maliyeti (örneğin 200$: 4 saat @ 50$/saat)
- c_e = tespit edilemeyen bir hatanın maliyeti (örn. 1000 $)
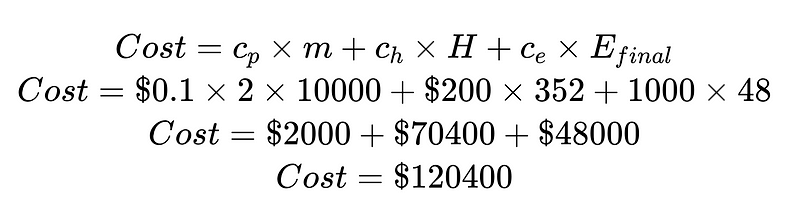
Maliyeti, insan müdahalesinin maliyetine ve tespit edilemeyen hataların maliyetine bölerek genel sistemi iyileştirebiliriz. Bu örnekte, insan müdahalesinin maliyeti (70,400 $) istenmeyen ve pahalıysa, yüksek güvenilirlikli sonuçları artırmaya odaklanabiliriz. Tespit edilemeyen hataların maliyeti (48,000 $) istenmeyen ve pahalıysa, tespit edilemeyen hata oranını azaltmak için Plus sözdizimi analizörlerini kullanabiliriz.
Elbette maliyet fonksiyonları, tanımladıkları durumların nasıl iyileştirilebileceğini keşfetmenin yolları olarak en yararlıdır.
Yukarıdaki senaryodan, tespit edilemeyen hataların sayısını, E_final, %50 oranında azaltmak için,
- p1 ve p2 = 0.8,
- v = 0.7 ve
- n = 0.6
Üç seçeneğimiz var:
- İkincil bir ayrıştırıcı olarak %50 doğruluk oranına sahip yeni bir dil bilgisi ayrıştırıcısı eklendi. Ancak bunun bir dezavantajı olduğunu unutmayın: Plus dil bilgisi ayrıştırıcılarını çalıştırmanın maliyeti, insan müdahalesinin artan maliyetiyle birlikte artıyor.
- Mevcut dil bilgisi ayrıştırıcılarının her birini %10 oranında iyileştirin. Bu, sözdizimsel analizcilerin gerçekleştirdiği görevin zorluğuna bağlı olarak mümkün olabilir veya olmayabilir.
- Denetçi sürecini %15 oranında iyileştirin. Bu da yine insan müdahalesiyle maliyeti artırıyor.
Yapay Zeka Güveninin Geleceği: Aşırı Hassasiyetle Güven Oluşturma
Yapay zeka sistemleri iş ve toplumun hayati yönlerine giderek daha fazla entegre oldukça, özellikle kritik uygulamalarda optimum doğruluğun peşinde koşmak giderek daha da zorunlu hale gelecektir. Yapay zeka karar alma süreçlerinde devrelerden ilham alan bu yaklaşımları benimseyerek, yalnızca verimli bir şekilde ölçeklenebilen değil, aynı zamanda tutarlı ve güvenilir performanstan kaynaklanan derin güveni de kazanabilen sistemler inşa edebiliriz. Gelecek, daha güçlü bireysel modellerde değil, stratejik insan gözetimiyle çoklu bakış açılarını birleştiren, dikkatlice tasarlanmış sistemlerde yatmaktadır.
Tıpkı dijital elektroniğin güvenilmez bileşenlerden evrilerek en önemli verilerimizi emanet ettiğimiz bilgisayarlara dönüşmesi gibi, yapay zeka sistemleri de artık benzer bir yolculukta. Bu makalede açıklanan çerçeveler, kritik görevdeki yapay zeka için nihayetinde standart mimari haline gelecek olan sistemlerin planlarını temsil ediyor; bu sistemler yalnızca güvenilirlik vaat etmekle kalmıyor, aynı zamanda bunu matematiksel olarak da garanti ediyor. Artık soru, yapay zeka sistemlerini neredeyse mükemmel doğrulukta inşa edip edemeyeceğimiz değil, bu prensipleri en önemli uygulamalarımıza ne kadar hızlı uygulayabileceğimizdir.
Yoruma kapalı.