

Ollama ve OpenAI'dan basit değerlendirmeler kullanılarak GPQA üzerinde DeepSeek-R1 damıtılmış modellerinin performans değerlendirmesi
Çıkarım yeteneklerini değerlendirmek için yerel olarak damıtılmış DeepSeek-R1 modelleri üzerinde GPQA-Diamond kıyaslamasını kurun ve çalıştırın.
Son model lansmanı DeepSeek-R1 Küresel yapay zeka topluluğunda geniş yankı buldu. Meta ve OpenAI'nin çıkarım modellerine benzer atılımlar gerçekleştirdi ve bunu çok daha kısa sürede ve çok daha düşük maliyetle gerçekleştirdi.
Ancak manşetlerin ve çevrimiçi abartıların ötesinde, tanınmış ölçütleri kullanarak bir modelin çıkarım yeteneklerini nasıl değerlendirebiliriz? Bu, yapay zeka uzmanları için önemli bir sorudur.
. Kullanıcı arayüzü Derin arama Yeteneklerini keşfetmeyi kolaylaştırır, ancak programlı olarak kullanılması daha derin içgörüler ve gerçek dünya uygulamalarına daha sorunsuz entegrasyon sağlar. Bu modellerin yerel olarak nasıl çalıştığını anlamak, gelişmiş kontrol ve çevrimdışı erişim de sağlar.

Bu makalede, nasıl kullanılacağını inceleyeceğiz Ollama و OpenAI'dan basit değerlendirmeler DeepSeek-R1 damıtılmış modellerinin çıkarım yeteneklerini kıyaslama ölçütüne göre değerlendirmek GPQA-Elmas Ünlü. Bu kriter, mantıksal akıl yürütme alanında yapay zekâ modellerinin değerlendirilmesinde en önemli araçlardan biri olarak kabul edilmektedir.
Sana GitHub deposu bağlantısı Bu makaleye eşlik eden.
(1) Akıl yürütmenin modelleri nelerdir?
DeepSeek-R1 ve OpenAI'nin o-serisi modelleri (örneğin, o1, o3) gibi çıkarım modelleri, çıkarım yapmak için takviyeli öğrenme kullanılarak eğitilen büyük dil modelleridir (LLM'ler). Bu modeller, yapay zeka alanında ileri düzey araçlar olup, makinelerin mantıksal düşünme ve karmaşık problemleri çözme yeteneklerindeki evrimin zirvesini temsil ediyor.
Sezgiler, cevap vermeden önce derinlemesine düşünmeyi ve cevap vermeden önce uzun bir içsel düşünce dizisi üretmeyi ifade eder. Karmaşık problemleri çözmede, programlamada, bilimsel akıl yürütmede ve ajan iş akışlarının çok adımlı planlanmasında üstündür. Bu kabiliyetleri onları ileri yazılım geliştirme, bilimsel araştırma ve karmaşık süreç otomasyonu gibi alanlarda vazgeçilmez kılmaktadır.
(2) DeepSeek-R1 modeli nedir?
DeepSeek-R1, özellikle şu amaçlar için tasarlanmış, son teknoloji ürünü, açık kaynaklı büyük dil modelidir (LLM). İleri düzey muhakeme. Ocak 2025'te araştırma makalesinde sunuldu "DeepSeek-R1: Takviyeli Öğrenme ile Büyük Dil Modellerinde Çıkarım Gücünü Artırma". DeepSeek-R1 yapay zeka alanında öncü bir modeldir.
Bu model, 671 milyar parametreli büyük dil modeli (LLM) mimarisine dayanmaktadır ve aşağıdaki yola dayalı kapsamlı takviyeli öğrenme (RL) kullanılarak eğitilmiştir:
- Artırmanın iki aşaması, gelişmiş muhakeme kalıplarını keşfetmeyi ve bunları insan tercihleriyle uyumlu hale getirmeyi amaçlamaktadır.
- İki aşamalı denetlenen ince ayar, modelin çıkarım yapma ve çıkarım yapmama kabiliyetleri için tohum görevi görür.
Örneğin, DeepSeek iki modeli eğitti:
- İlk model, Derin Arama-R1-Sıfır, takviyeli öğrenme kullanılarak eğitilmiş bir çıkarım modelidir ve ikinci modeli eğitmek için veri üretir, DeepSeek-R1.
- Bunu, nihai sonuçlarına göre yalnızca yüksek kaliteli çıktıların tutulduğu çıkarım izleri üreterek başarır.
- Bu, çoğu modelin aksine, bu eğitim kanalındaki takviyeli öğrenme (RL) örneklerinin insanlar tarafından düzenlenmediği, ancak modelin kendisi tarafından oluşturulduğu anlamına gelir.
Sonuç olarak, model, aşağıdaki gibi önde gelen modellerle benzer performansa ulaşmıştır: OpenAI'nin o1 modeli Matematik, programlama ve karmaşık akıl yürütme gibi görevlerde.
(3) DeepSeek-R1'den damıtma sürecini ve damıtılmış modelleri anlamak
Tam modele ek olarak, DeepSeek-R1'den damıtılmış farklı boyutlarda (1.5B, 7B, 8B, 14B, 32B, 70B) altı küçük yoğun modeli (DeepSeek-R1 olarak da adlandırılır) de açık kaynaklı hale getirdiler. Qwen أو lama Temel model olarak.
Damıtma Daha önce eğitilmiş daha büyük ve daha güçlü bir modelin ("öğretmen") performansını taklit etmek üzere daha küçük bir modelin ("öğrenci") eğitildiği bir tekniktir.
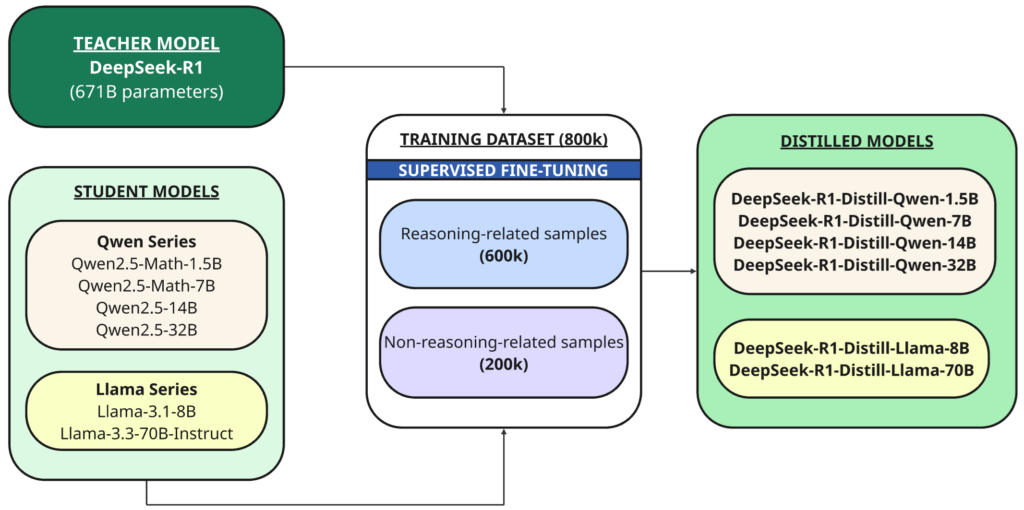
Bu durumda öğretmen 1B DeepSeek-R671 modelidir ve öğrenciler bu açık kaynaklı temel model kullanılarak damıtılan altı modeldir:
- Qwen2.5 — Matematik-1.5B
- Qwen2.5 — Matematik-7B
- Qwen2.5 — 14B
- Qwen2.5 — 32B
- Lama-3.1 — 8B
- Llama-3.3 — 70B-Talimat
DeepSeek-R1, çıkarımsal ve çıkarımsal olmayan örneklerin bir karışımı olan 800,000 eğitim örneği üretmek için bir öğretmen modeli olarak kullanıldı ve damıtıldı. denetlenen ince ayar Temel modeller için (1.5B, 7B, 8B, 14B, 32B ve 70B).
Peki, neden damıtmayı yapıyoruz?
Amaç, DeepSeek-R1 671B gibi daha büyük modellerin çıkarım yeteneklerini daha küçük ve daha verimli modellere aktarmaktır. Bu, daha küçük modellerin daha hızlı ve daha kaynak verimli bir şekilde karmaşık çıkarım görevlerini ele almasını sağlar.
Ayrıca DeepSeek-R1'in çok sayıda parametresi (671 milyar) bulunuyor ve bu da onu çoğu tüketici cihazında çalıştırmayı zorlaştırıyor.
Maksimum birleşik belleği 128 GB olan en güçlü MacBook Pro bile, 671 milyar parametreli bir modeli çalıştırmaya yetmiyor.
Bu nedenle, damıtılmış modeller, bunların sınırlı hesaplama kaynaklarına sahip cihazlarda dağıtılma olasılığını açar.
ulaşıldı Tembellikten kurtulmak Orijinal 1 milyar parametreli DeepSeek-R671 modelinin boyutunun sadece 131 GB'a düşürülmesiyle elde edilen dikkate değer bir başarı, boyutta %80'lik dikkate değer bir azalma anlamına geliyor. Ancak 131 GB VRAM gereksinimi, özellikle kısıtlı kaynaklara sahip cihazlar üzerinde çalışan geliştiriciler için önemli bir engel olmaya devam ediyor. Bu başarı, büyük yapay zeka modellerinin daha geniş bir kullanıcı kitlesine ulaşması yolunda önemli bir adım teşkil ediyor.
(4) En uygun damıtılmış modelin seçimi
Altı farklı boyutta damıtılmış model arasından seçim yapabileceğiniz için, doğru modeli belirlemek büyük ölçüde yerel ekipmanınızın yeteneklerine bağlıdır.
Yüksek performanslı GPU'lara veya maksimum performansa ihtiyaç duyan CPU'lara sahip olanlar için daha büyük DeepSeek-R1 modelleri (32B ve üzeri) idealdir; hatta kuantum 671B versiyonu bile uygundur.
Ancak, kaynaklarınız sınırlıysa veya daha hızlı yapım sürelerini tercih ediyorsanız (benim gibi), 8B veya 14B gibi daha küçük damıtılmış varyantlar daha iyi bir seçenektir. Bu, performans ve kaynak gereksinimlerini dengeler.
Bu proje için saflaştırılmış DeepSeek-R1 modelini kullanacağım. Qwen-14BKarşılaştığınız donanım kısıtlamalarına karşılık gelen . Bu model (14B), doğruluk ve hız arasında mükemmel bir uzlaşmayı temsil ediyor ve bu da onu benim geliştirme ortamım için mükemmel bir uyum haline getiriyor.
(5) Büyük dil modellerinin çıkarım yeteneğini değerlendirme kriterleri
Büyük dil modelleri (LLM'ler) genellikle dil anlama, kod oluşturma, talimatları izleme ve soruları yanıtlama gibi çeşitli görevlerdeki performanslarını belirleyen standartlaştırılmış ölçütler kullanılarak değerlendirilir. Yaygın örnekler arasında şunlar gibi metrikler bulunur: MMLU, Ve İnsanDeğerlendirmesi, Ve MGSM. Bu metrikler büyük dil modellerinin yeteneklerini değerlendirmek için önemlidir.
Büyük bir dil modelinin akıl yürütme yeteneğini ölçmek için, akıl yürütmeye yoğun olarak odaklanan ve yüzeysel görevlerin ötesine geçen, daha zorlayıcı ölçütlere ihtiyacımız var. İleri düzey muhakeme yeteneklerinin değerlendirilmesine odaklanan bazı yaygın örnekler şunlardır:
(i) AIME 2024 Sınavı: Rekabetçi Matematik
- Sayıldı Amerikan Davetli Matematik Sınavı (AIME) 2024 Matematiksel muhakemede büyük dil modelleri (LLM) yeteneklerini değerlendirmek için sağlam bir ölçüt.
- Bu sınav, karmaşık ve çok adımlı problemler sunduğu için rekabetçi matematikte önemli bir meydan okumayı temsil eder. Sınav, büyük dil modellerinin karmaşık soruları anlama, ileri düzey akıl yürütme ve hassas sembolik işlemler yapma yeteneğini test eder. AIME, karmaşık matematiksel problem çözme becerilerinin değerlendirilmesinde önemli bir ölçüttür.
(ii) Codeforces – Rekabet Kanunu
- Dayanmaktadır Codeforces Standard Algoritmik zorluklarıyla bilinen bir platform olan Codeforces'un gerçek dünya rekabetçi programlama problemlerini kullanarak büyük dil modelinin çıkarım yeteneğinin değerlendirilmesi (LLM). Codeforces, karmaşık problemleri çözmek için yapay zeka modellerinin yeteneklerini değerlendirmede altın standarttır.
- Bu problemler, büyük dil modelinin (LLM) karmaşık talimatları anlama, mantıksal ve matematiksel akıl yürütme, çok adımlı çözümler planlama ve doğru ve verimli kod üretme yeteneğini test eder. Bu problemler, algoritmalar ve veri yapıları konusunda derin bir anlayış ve problemi çalıştırılabilir koda dönüştürme yeteneği gerektirir.
(iii) GPQA Diamond – Doktora düzeyinde bilimsel sorular
- GPQA-Diamond, seçilmiş bir alt kümedir En zor sorular Standarttan GPQA (Lisansüstü Fizik Soru Cevapları) En geniş kapsamlı ve özel olarak LLM modellerinin ileri doktora seviyesindeki konularda çıkarım yapma yeteneğinin sınırlarını zorlamak için tasarlanmıştır. Bu standart, yapay zekanın karmaşık bilimsel kavramları anlama ve çıkarsama becerisine yönelik gerçek bir meydan okumayı temsil ediyor.
- GPQA kavramsal ve hesaplamaya dayalı bir dizi lisansüstü soru içerirken, GPQA-Diamond yalnızca en zor soruları ve yoğun muhakeme gerektiren soruları ayırır.
- Bu kriter "Google'a dayanıklı" olarak değerlendiriliyor, yani kısıtlanmamış web erişimi olsa bile bu soruya cevap vermek zor. Bu, onu büyük dil modellerinin bağımsız olarak akıl yürütme yeteneğini değerlendirmek için değerli bir araç haline getirir.
- İşte GPQA-Diamond sorusuna bir örnek:
### GPQA Diamond - Örnek Soru (Moleküler Biyoloji) Ökaryotik bir hücre, makromoleküler yapı taşlarını enerjiye dönüştürmek için bir mekanizma geliştirmiştir. Bu süreç hücresel enerji fabrikaları olan mitokondrilerde gerçekleşir. Redoks tepkimeleri serisinde besinlerden gelen enerji fosfat grupları arasında depolanır ve evrensel hücresel para birimi olarak kullanılır. Enerji yüklü moleküller, tüm hücresel süreçlerde görev almak üzere mitokondriden dışarı taşınır. Yeni bir diyabet ilacı keşfettiniz ve bunun mitokondri üzerinde bir etkisi olup olmadığını araştırmak istiyorsunuz. HEK293 hücre hattınızla bir dizi deney kurdunuz. Aşağıda listelenen deneylerden hangisi ilacınızın mitokondriyal rolünü keşfetmenize yardımcı olmaz: (A) Glikoz Alım Kolorimetrik Analiz Kiti'nin ardından mitokondrilerin diferansiyel santrifüjleme ekstraksiyonu (B) 2.5 µM 5,5',6,6'-Tetrakloro-1,1',3,3'-tetraetilbenzimidazolilkarbosiyanin iyodür ile etiketlemeden sonra akış sitometrisi (C) Üst faza 5 µM lüsiferin eklendikten sonra rekombinant lüsiferaz ve lüminometre okuması ile hücrelerin transformasyonu (D) Hücrelerin Mito-RTP boyama işleminden sonra konfokal floresan mikroskopisi
Bu projede, Sonuçlandırmada standart olarak GPQA-Diamond'ı kullanıyoruz., kullandığım gibi OpenAI و Derin Arama Çıkarım modellerini değerlendirmek. GPQA-Diamond’ın değerlendirme standardı olarak seçilmesi, yapay zeka geliştirme alanında ne kadar zor ve önemli olduğunun kanıtıdır.
(6) Kullanılan araçlar
Bu projede ağırlıklı olarak şunları kullanıyoruz: Ollama و basit değerlendirmeler OpenAI'dan. Ollama, büyük dil modellerini yerel olarak çalıştırmak için güçlü bir platformdur; simple-evals ise bu modellerin performansını değerlendirmek için bir çerçeve sağlar.
(i) Ollama
Ollama Bilgisayarımızda veya yerel sunucumuzda büyük dil modelleri (LLM) çalıştırmayı kolaylaştıran açık kaynaklı bir araçtır. Olama, yapay zeka modellerini yerel olarak çalıştırmak için ideal bir platformdur.
İndirmeler ve ortam kurulumu gibi görevleri yöneten bir yönetici ve çalışma zamanı görevi görür. Bu, kullanıcıların sürekli internet bağlantısına ihtiyaç duymadan veya bulut hizmetlerine güvenmeden bu modellerle etkileşime girmesine olanak tanır. Yerel büyük dil modellerini (LLM) yönetmek Olama'nın temel bir özelliğidir.
DeepSeek-R1 dahil olmak üzere birçok büyük açık kaynaklı dil modelini destekler ve macOS, Windows ve Linux ile platformlar arası uyumludur. Ayrıca, minimum uğraşla kolay kurulum ve kaynakların verimli kullanımı imkânı sunar. Ollama, yapay zekanın gücünden doğrudan cihazınızda yararlanmanızı sağlar.
ÖnemliYerel makinenizde şunlar olduğundan emin olun: GPU erişilebilirliği Ollama için bu, performansı önemli ölçüde hızlandırıyor ve sonraki kıyaslama işlemlerini CPU'ya kıyasla daha verimli hale getiriyor. Komutu çalıştırın
nvidia-smiGPU'nun algılanıp algılanmadığını kontrol etmek için terminale giriyoruz. Bu prosedür, cihazın yeteneklerinin en üst düzeye çıkarılarak modellerin yüksek verimlilikle çalıştırılmasını sağlar.
(ii) Dil modellerini değerlendirmek için OpenAI basit değerlendirme kütüphanesi
Hazırlamak basit değerlendirmeler Düşünce zinciri yönlendirmesiyle sıfır atış değerlendirme metodolojisini kullanarak dil modellerini değerlendirmek için tasarlanmış hafif bir kütüphane. MMLU, MATH, GPQA, MGSM ve HumanEval gibi popüler değerlendirme ölçütlerini içeren bu kütüphane, karmaşık çıkarım görevlerinde yapay zeka modellerinin performansını değerlendirmek için gerçek dünya kullanım senaryolarını simüle etmeyi amaçlamaktadır.
Bazılarınız OpenAI'nin en popüler ve kapsamlı değerlendirme kütüphanesi olan Değerlendirmeler, simple-evals'den farklıdır.
Aslında sayfa şunu gösteriyor README Simple-evals spesifikasyonu, bunun kütüphanenin yerini alması için tasarlanmadığını belirtir. Değerlendirmeler.
Peki simple-evals'ı neden kullanıyoruz?
Basit cevap şudur: basit değerlendirmeler Kütüphanenin sahip olmadığı hedeflediğimiz çıkarım standartlarına (GPQA gibi) yönelik yerleşik değerlendirme metinleriyle birlikte geliyor. Değerlendirmeler.
Ayrıca simple-evals dışında dilde doğrudan ve yerel bir yol sağlayan başka bir araç veya platform bulamadım. Python Özellikle Ollama ile çalışırken GPQA gibi birçok önemli standardı çalıştırmak.
(7) Değerlendirme sonuçları
Değerlendirme kapsamında şunları seçtim: 20 rastgele soru GPQA-Diamond soru setinden 198 soru üzerinde çalışın Form 14B Damıtıcı. Toplam 216 dakika sürdü, soru başına yaklaşık 11 dakika.
Sonuç biraz hayal kırıklığı yarattı çünkü kaydedildi 10% Sadece bu sonuç, 73.3B DeepSeek-R1 modeli için bildirilen %671'lük sonuçtan önemli ölçüde düşüktür.
Fark ettiğim asıl sorun, yoğun içsel muhakeme sırasında, Model genellikle herhangi bir yanıt üretmede başarısız oldu (örneğin, çıktının son satırları olarak çıkarım kodlarını döndürdü) veya beklenen çoktan seçmeli formatla uyuşmayan bir yanıt sağladı (örneğin, yanıt: A).
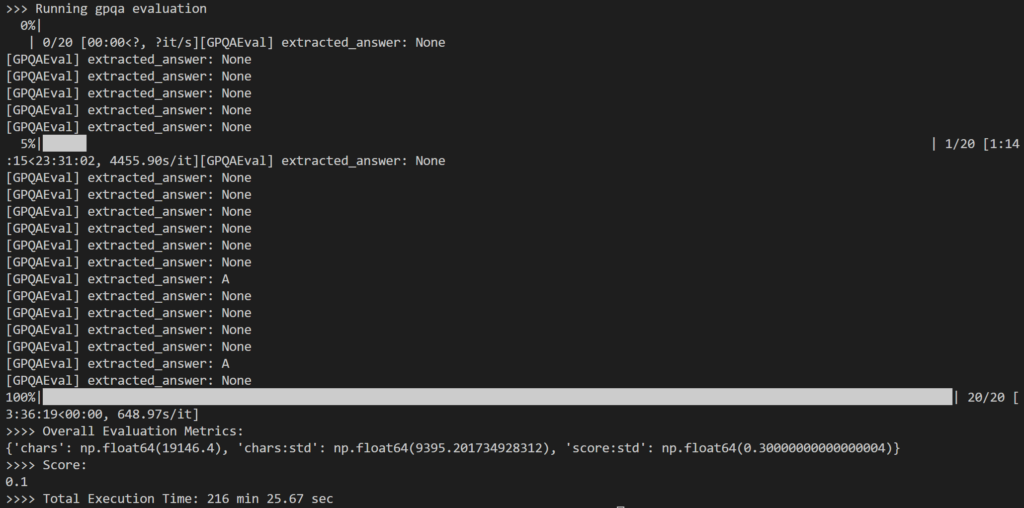
Yukarıda görüldüğü gibi çıktıların çoğu şu şekilde sonuçlandı: None Çünkü simple-evals'deki regex mantığı LLM yanıtındaki beklenen cevap örüntüsünü algılayamadı.
iken insan benzeri akıl yürütme Sorulara cevap verme konusunda daha isabetli bir performans beklediğimden, gözlemlemek ilginçti.
Ayrıca internette kullanıcıların daha büyük 32B modelinin bile o1 kadar iyi çalışmadığından bahsettiğini gördüm. Bu durum, özellikle uzun çıkarımlar üretmelerine rağmen doğru cevaplar sağlamada zorluk çektikleri durumlarda, damıtılmış çıkarım modellerinin kullanışlılığı konusunda şüpheler doğurmuştur.
Ancak GPQA-Diamond oldukça zorlu bir kıyaslama olduğundan, bu modeller daha basit çıkarım görevleri için hâlâ yararlı olabilir. Daha düşük hesaplama gereksinimleri de işi daha kolay hale getiriyor.
Ayrıca DeepSeek ekibi, kıyaslama sürecinin bir parçası olarak birden fazla test çalıştırılmasını ve sonuçların ortalamasının alınmasını önerdi; ancak zaman kısıtlamaları nedeniyle bunu gözden kaçırdım.
(8) Ayrıntılı adım adım kılavuz
Şu ana kadar temel kavramları ve ana sonuçları ele aldık.
Eğer uygulamalı, teknik bir deneyime hazırsanız, bu bölüm dahili mekanizmalara ve adım adım uygulamaya dair derinlemesine bir bakış sağlar. Bu pratik teknik rehber, sistemin nasıl çalıştığına dair kapsamlı bir anlayış sağlayacaktır.
Görüntülemek (veya kopyalamak) için Companion GitHub deposu Takip etmek. Sanal ortam kurulum gereksinimlerine buradan ulaşabilirsiniz. Burada.
(i) İlk kurulum – Ollama
Ollama'yı indirerek başlıyoruz. Ziyaret etmek
Ollama İndirme Sayfası, işletim sisteminizi seçin ve ilgili kurulum talimatlarını izleyin.
Kurulum tamamlandıktan sonra Ollama uygulamasını çift tıklayarak (Windows ve macOS için) veya şu komutu çalıştırarak Ollama'yı başlatın: ollama serve Terminalde.
(ii) İlk kurulum – OpenAI simple-evals
Basit değerlendirmelerin kurulumu nispeten benzersizdir.
Simple-evals kendini bir kütüphane olarak sunarken, Dosyaların yokluğu __init__.py Depoda olması, düzgün bir Python paketi olarak yapılandırılmadığı anlamına gelir., deponun yerel olarak klonlanmasından sonra içe aktarma hatalarına yol açar. Bu, yazılım mühendisliğinde yaygın olarak kullanılan anlamda standart bir Python paketi olmadığı anlamına gelir.
Ayrıca PyPI'da yayınlanmadığı ve standart paketleme dosyalarından yoksun olduğu için setup.py أو pyproject.tomlÜzerinden kurulum yapılamaz pip. Bu durum yeni geliştiriciler için biraz zorluk yaratıyor.
Neyse ki, kullanabiliriz Git alt modülleri Doğrudan alternatif çözüm olarak. Bu modüller, bir Git deposunu başka bir deponun içine eklemenize olanak tanır ve böylece bağımlılıkları yönetmeniz kolaylaşır.
“`html
Git alt modülleri, başka bir Git deposunun içeriklerini projemize dahil etmemize olanak tanır. Dosyaları harici bir depoda (örneğin simple-evals) çeker, ancak geçmişlerini ayrı tutar.
Basit değerlendirmelerin içeriğini çıkarmak için iki yöntemden birini (A veya B) seçebilirsiniz:
(a) Proje deposunu klonlarsanız
Proje havuzum zaten şunları içeriyor: simple-evals Alt modül olarak, şu komutu çalıştırabilirsiniz:
git submodule update --init --recursive(b) Yeni oluşturulan bir projeye ekliyorsanız.
simple-evals'ı alt modül olarak manuel olarak eklemek için şunu çalıştırın:
git submodule add https://github.com/openai/simple-evals.git simple_evalsملاحظة: O simple_evals Sonunda (ile) alt çizgi) çok önemlidir. Klasör adını belirtir, bunun yerine bir tire kullanır (yani basit-(değerlendirmeler) daha sonra ithalat sorunlarına yol açabilir.
Son adım (her iki yöntem için de)
Depo içeriğini çektikten sonra bir dosya oluşturmanız gerekmektedir. __init__.py Klasörde boş simple_evals Yeni oluşturulan birim, bir birim olarak içe aktarılabilir. Bunu manuel olarak oluşturabilir veya aşağıdaki komutu kullanabilirsiniz:
touch simple_evals/__init__.py(iii) Ollama aracılığıyla DeepSeek-R1 modelinin çekilmesi
Bir sonraki adım, bu komutu kullanarak seçtiğiniz yerel olarak damıtılmış modeli (örneğin, 14B) indirmektir:
Mevcut DeepSeek-R1 modellerinin listesini Ollama'da bulabilirsiniz. Burada. En iyi performans için şablonun en son sürümünü kullanmanız önerilir.
ollama pull deepseek-r1:14b(Dördüncü) Ayarları belirtin
Ayarlar YAML dosyasında parametreleri aşağıda gösterildiği gibi tanımlıyoruz:
# config/config.yaml MODEL_NAME: "deepseek-r1:14b" # Model adı (Ollama model listesiyle eşleşir) MODEL_TEMPERATURE: 0.6 # DeepSeek-R0.5 için 0.7 ile 1 arasında ayarlayın EVAL_BENCHMARK: "gpqa" GPQA_VARIANT: "diamond" EVAL_N_EXAMPLES: 20
Model sıcaklığı şu şekilde ayarlandı: 0.6 (Tipik varsayılan değer olan 0 ile karşılaştırıldığında). Bu, DeepSeek'in 0.5 ila 0.7 (önerilen 0.6) sıcaklık aralığını öneren kullanım önerilerini takip eder. Sonsuz tekrarları veya tutarsız çıktıları önlemek için. Bu ayar çıktı kalitesini artırmak ve tutarlılığını sağlamak için gereklidir.
Kontrol etme şansını kaçırmayın DeepSeek-R1'in benzersiz ve ilgi çekici kullanım önerileri – özellikle kıyaslama amaçlı – DeepSeek-R1 modellerini kullanırken optimum performansı garantilemek için.
EVAL_N_EXAMPLES Bu, değerlendirmede kullanılan 198 soruluk tam setten soru sayısını belirlemek için kullanılan parametredir. Bu parametre, değerlendirme sürecini mevcut kaynaklara ve belirli test hedeflerine göre ayarlamak için gereklidir.
(v) Sampler kodunun kurulumu
Simple-evals çerçevesinde Ollama tabanlı dil modellerini desteklemek için, adında özel bir sarmalayıcı sınıf oluşturuyoruz. OllamaSampler Ve onu içeride tut utils/samplers/ollama_sampler.py. Örnekleyici, dil modellerinin performansını test etme ve değerlendirmede önemli bir bileşendir.
# utils/samplers/ollama_sampler.py ollama sınıfını içe aktar OllamaSampler: def __init__(self, model_name=Hiçbiri, sıcaklık=0): self.model_name = model_name self.sıcaklık = sıcaklık def __call__(self, istem_iletileri): istem_metni = istem_iletileri[-1]["içerik"] yanıt = ollama.chat( model=self.model_name, iletiler=[{"rol": "kullanıcı", "içerik": istem_metni}], seçenekler={"sıcaklık": self.sıcaklık} ) yanıt_içeriği = yanıt["ileti"]["içerik"] yanıt_içeriğini döndür def _pack_message(self, içerik, rol): return {"rol": rol, "içerik": içerik}
Bu bağlamda, bu şu anlama gelir: örnekleyici (Örnekleyici) Verilen bir komut istemine dayalı olarak bir dil modelinden çıktı üreten bir Python sınıfı. Bu araç, modelden çeşitli ve temsili yanıtlar üretilmesini sağlamak için çok önemlidir.
Simple-evals'deki örnekleyiciler yalnızca OpenAI ve Claude gibi sağlayıcıları kapsadığından, Ollama ile uyumlu bir arayüz sağlayan bir örnekleyici sınıfına ihtiyacımız var. Bu, değerlendirme çerçevesiyle kusursuz entegrasyonu sağlar.
kalkmak OllamaSampler Bir GPQA soru istemini çıkarır, belirtilen bir sıcaklıkta forma gönderir ve düz metin yanıtını döndürür. Sıcaklık, çıktının rastgeleliğini kontrol eden önemli bir parametredir.
Yöntem dahil _pack_message Çıktı formatının simple-evals'deki değerlendirme betiklerinin beklediği formatla eşleştiğinden emin olmak için. Bu, tutarlılığı ve analiz kolaylığını sağlar.
6. Bir değerlendirme betiği oluşturun
Aşağıdaki kod, bir dosyada değerlendirme uygulamasının nasıl kurulacağını göstermektedir. main.py, kategorinin kullanımı dahil GPQAEval GPQA kıyaslama testlerini çalıştırmak için simple-evals kütüphanesinden yararlanın.
İşlev run_eval() Ollama aracılığıyla büyük dil modellerini (LLM) GPQA gibi standartlarla karşılaştırarak test eden yapılandırılabilir bir değerlendirme çalışma zamanı aracıdır. Bu fonksiyon modellerin performansını doğru bir şekilde değerlendirmek için gereklidir.
# main.py def run_eval(): start_time = time.time() # Yapılandırma dosyasını yükle config = load_config("config/config.yaml") # Ollama örnekleyicisini başlat (Ollama sohbeti etrafında sarmalayıcı) ollama_sampler = OllamaSampler(model_name=config["MODEL_NAME"], temperature=config["MODEL_TEMPERATURE"] ) # EVAL_BENCHMARK'a göre kullanılacak değerlendirme sınıfını seç eval_benchmark = config["EVAL_BENCHMARK"] # GPQA print(f">>> {eval_benchmark} değerlendirmesi çalıştırılıyor") if eval_benchmark == "gpqa": eval_class = GPQAEval eval_kwargs = { "n_repeats": config["EVAL_N_REPEATS"], # Varsayılan 1 "num_examples": config["EVAL_N_EXAMPLES"], # 20 olarak ayarla "variant": config["GPQA_VARIANT"], # GPQA-Diamond alt kümesi } değilse: ValueError(f"Unknown EVAL_BENCHMARK '{eval_benchmark}'." yükselt) # Uygun değerlendirmeyi başlat ve çalıştır değerlendirici = eval_class(**eval_kwargs) sonuçlar = değerlendirici(ollama_örnekleyici) # Örnekleyici ile değerlendirmeyi yürüt bitiş_zamanı = zaman.zaman() geçen_saniyeler = bitiş_zamanı - başlangıç_zamanı dakika, saniye = divmod(geçen_saniyeler, 60) # Toplam harcanan zamanı hesapla # Döndürülen sonuçlar, Tek Değerlendirme Sonuçları ve toplanmış ölçümlerin listesini içeren bir EvalSonucudur print(">>>> Genel Değerlendirme Ölçümleri:", results.metrics) print(">>>> Puan:", results.score) print(f">>>> Toplam Yürütme Süresi: {int(dakika)} dk {saniye:.2f} sn") if __name__ == "__main__": # GPQA değerlendirme yürütmesini çalıştır run_eval()
Fonksiyon, yapılandırma dosyasından ayarları yükler, simple-evals'tan uygun değerlendirme sınıfını kurar ve modeli tekdüze bir değerlendirme sürecinden geçirir. Bir dosyaya kaydedilir. main.py, komutu kullanılarak çalıştırılabilir python main.py. Bu, tutarlı ve tekrarlanabilir bir değerlendirme sürecinin sağlanmasını garanti eder.
Yukarıdaki adımları izleyerek DeepSeek-R1 damıtılmış modelinde GPQA-Diamond kıyaslamasını başarıyla kurduk ve yürüttük. Bu süreç, modelin yetenekleri hakkında değerli bilgiler sağlar.
Sonuç olarak
Bu makalede, Ollama ve OpenAI'nin basit değerlendirmeleri gibi araçları DeepSeek-R1'den damıtılan modelleri keşfetmek ve değerlendirmek için nasıl birleştirebileceğimizi inceliyoruz; özellikle Büyük dil modellerinin performans değerlendirmesi.
Damıtılmış modeller, GPQA-Diamond gibi zorlu çıkarım ölçütlerinde henüz orijinal 671 milyar parametreli modelle eşleşmeyebilir. Ancak, damıtmanın büyük dil modelleri (LLM) çıkarım yeteneklerine erişimi nasıl genişletebileceğini göstermektedir. Büyük dil modellerine erişimin iyileştirilmesi Bu alanda önemli bir hedef.
Karmaşık doktora düzeyindeki görevlerde daha düşük performansa rağmen, bu daha küçük varyantlar daha az zorlu senaryolarda uygulanabilir olabilir ve daha geniş bir cihaz yelpazesinde verimli yerel dağıtımın önünü açabilir. Bu, şuna katkıda bulunur: Büyük dil modellerini yerel olarak dağıtın Verimli bir şekilde.
Yoruma kapalı.