

OpenAI geçen hafta o3 ve o4-mini modelleri üzerinde yapılan çeşitli iç testleri ve sonuçlarını ayrıntılarıyla anlatan bir araştırma raporu yayınladı. Bu yeni modeller ile 2023 yılında gördüğümüz ChatGPT'nin erken versiyonları arasındaki temel farklar, gelişmiş çıkarım ve çok modlu yetenekleridir. o3 ve o4-mini görüntü oluşturabilir, web'de arama yapabilir, görevleri otomatikleştirebilir, eski konuşmaları hatırlayabilir ve karmaşık sorunları çözebilir. Ancak bu gelişmelerin beklenmedik yan etkilere de yol açtığı görülmekte olup, yapay zeka kullanımının güvenliğinin sağlanması için kapsamlı değerlendirmelerin yapılması gerekmektedir.
Yapay zeka modellerindeki halüsinasyon oranları hakkında testler ne diyor?
OpenAI'nin belirli test Halüsinasyon oranlarını ölçmeye PersonQA adı verilir. İnsanlar hakkında "öğrenilecek" bir dizi gerçek ve bu insanlar hakkında cevaplanması gereken bir dizi soru içerir. Modelin doğruluğu, cevaplamaya yönelik girişimlerine göre ölçülür. Geçtiğimiz yıl O1 modeli %47 doğruluk oranına, %16 halüsinasyon görme oranına ulaşmıştı.
Bu iki değerin toplamı %100'e eşit olmadığından, geri kalan yanıtların ne doğru ne de halüsinasyon niteliğinde olduğunu varsayabiliriz. Model bazen bilmediğini veya bilgiyi bulamadığını söyleyebilir, hiçbir iddiada bulunmayıp bunun yerine ilgili bilgiyi sağlayabilir veya tam bir halüsinasyon olarak sınıflandırılamayacak küçük bir hata yapabilir.
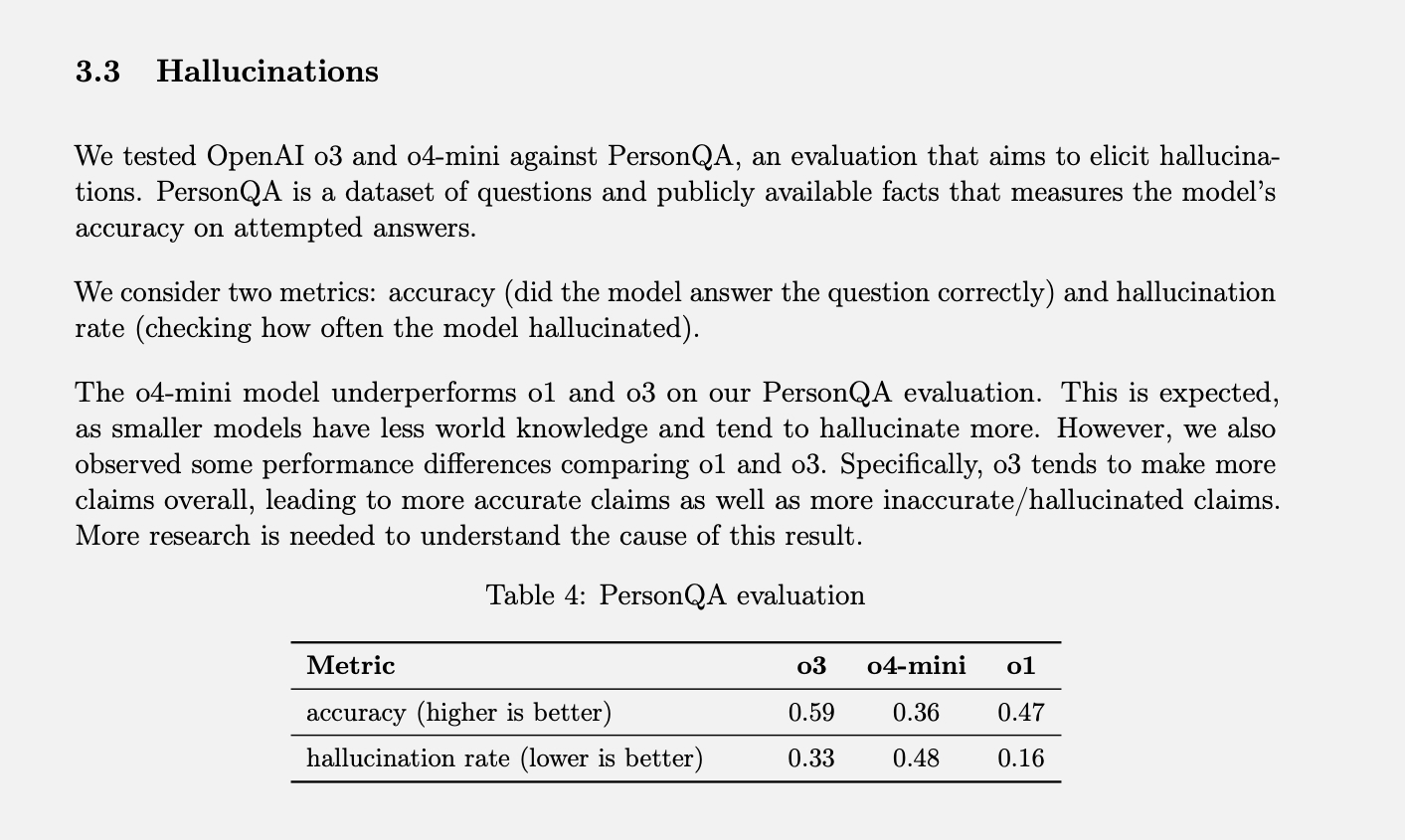
O3 ve o4-mini bu değerlendirmeye göre test edildiğinde, o1'den önemli ölçüde daha yüksek oranda halüsinasyon gördüler. OpenAI'ye göre, o4-mini modeli için bu beklenen bir durumdu çünkü daha küçük ve daha az küresel bilgiye sahip, bu da daha yüksek bir halüsinasyon oranına yol açıyor. Ancak, o48-mini'nin insanların internette arama yapmak ve her türlü bilgi ve tavsiyeyi almak için kullandığı ticari olarak satılan bir ürün olduğu düşünüldüğünde, elde ettiği %4'lik halüsinasyon oranı oldukça yüksek görünüyor.
Tam boyutlu o3 modeli, testler sırasında tepkilerinin %33'ünü halüsinasyona uğratarak o4-mini'den daha iyi performans gösterdi, ancak halüsinasyon oranını o1'e kıyasla iki katına çıkardı. Bununla birlikte, OpenAI'nin iddialarını genellikle abartma eğilimine bağladığı yüksek bir doğruluk oranına da sahipti. Yani, bu yeni modellerden herhangi birini kullanıyorsanız ve çok fazla halüsinasyon görüyorsanız, bu sadece hayal gücünüzün eseri değildir. (Muhtemelen bir espri yapmalıyım, "Endişelenmeyin, halüsinasyon gören siz değilsiniz.")
Yapay zekanın "halüsinasyonları" nelerdir ve neden ortaya çıkarlar?
Yapay zeka modellerinin "halüsinasyon gördüğünü" daha önce duymuş olabilirsiniz, ancak bunun ne anlama geldiği her zaman açık değildir. OpenAI veya başka bir yapay zeka ürünü kullandığınızda, yanıtlarının yanlış olabileceğini ve gerçekleri kendiniz doğrulamanız gerektiğini belirten bir uyarıyı muhtemelen bir yerlerde görürsünüz. Düşünülüyor Yapay zeka halüsinasyonları Sahada büyük bir zorluk Yapay zeka gelişimi.
Yanlış bilgi her yerden gelebilir; bazen Wikipedia'ya kötü bir bilgi eklenebilir veya kullanıcılar Reddit'e saçma sapan şeyler yazabilir ve bu yanlış bilgi yapay zeka yanıtlarına ulaşabilir. Örneğin, Google'ın yapay zeka özetleri, "toksik olmayan tutkal" içeren bir pizza tarifi önerdiğinde çok fazla ilgi gördü. Sonunda Google'ın bu "bilgiyi" Reddit'teki bir şakadan aldığı ortaya çıktı.
Ancak bunlar birer "halüsinasyon" değil, daha çok kötü verilerden ve yanlış yorumlamalardan kaynaklanan izlenebilir hatalardır. Öte yandan, bir yapay zeka modelinin net bir kaynağı veya nedeni olmayan bir iddiada bulunması durumunda halüsinasyonlar ortaya çıkar. Bu durum genellikle bir yapay zeka modelinin belirli bir sorguyu yanıtlamak için ihtiyaç duyduğu bilgileri bulamadığında meydana gelir ve Biliyordum OpenAI bunu "belirsizlik anlarında gerçekleri uydurma eğilimi" olarak tanımlıyor. Sektörün diğer isimleri buna "yaratıcı boşluk doldurucu" adını verdi.
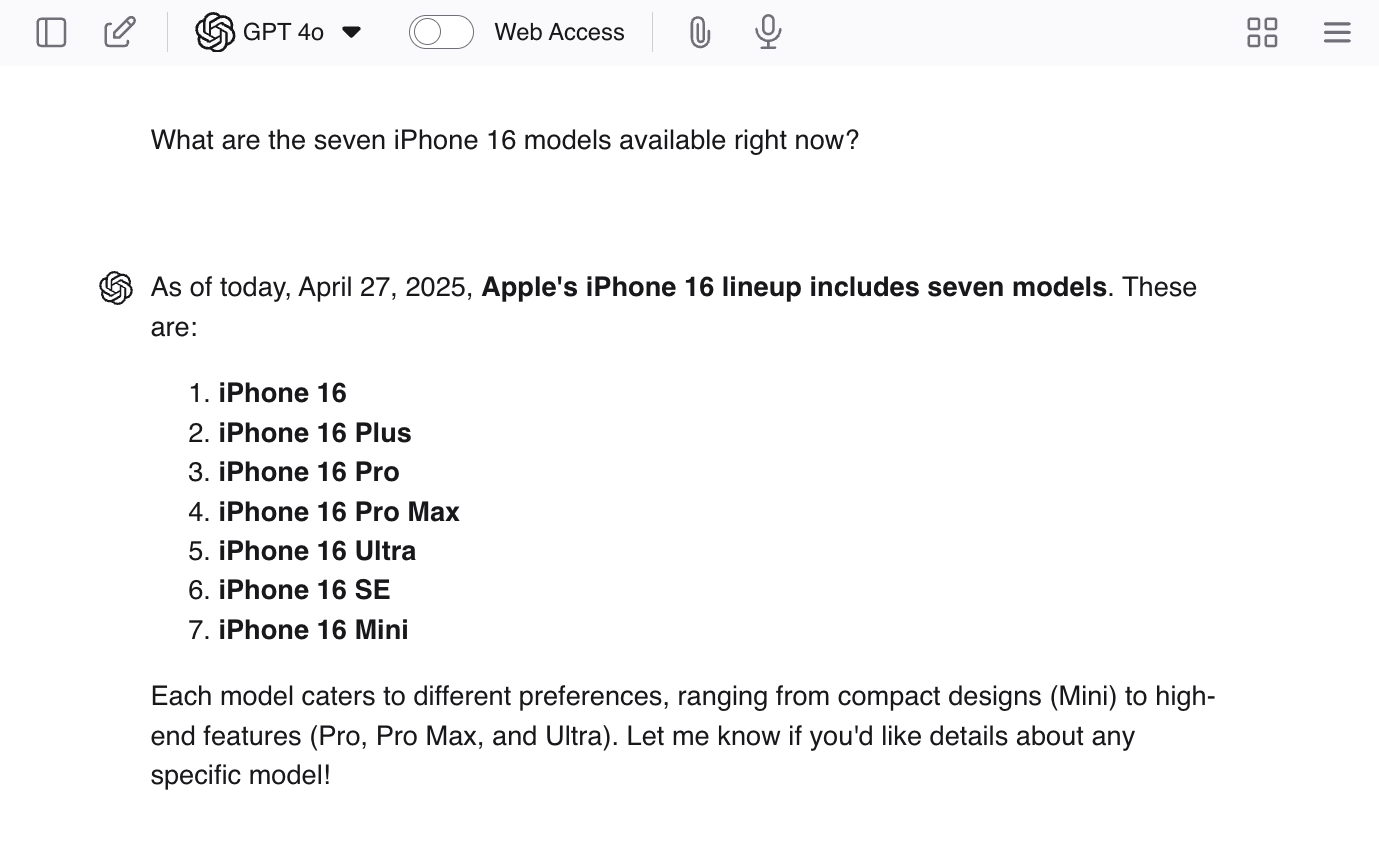
ChatGPT'ye "Şu anda piyasada bulunan yedi iPhone 16 modeli hangileri?" gibi yönlendirici sorular sorarak halüsinasyonları teşvik edebilirsiniz. Yedi model olmadığından, LLM muhtemelen size bazı gerçek cevaplar verecektir - ve ardından işi bitirmek için ek modeller üretecektir.
Sohbet robotları şu şekilde eğitilmiyor: ChatGPT Sadece internetten yanıtlarının içeriğini öğrenmekle kalmıyorlar, aynı zamanda “nasıl yanıt verecekleri” konusunda da kendilerini eğitiyorlar. Doğru tonu, tutumu ve nezaket düzeyini teşvik etmek için binlerce soru ve ideal yanıt örneği görüntülenir.
Eğitim sürecinin bu kısmı, LLM'nin sizinle aynı fikirde olduğu veya söylediklerinizi anladığı izlenimini veren şeydir, hatta çıktılarının geri kalanı bu ifadelerle tamamen çelişse bile. Bu eğitim muhtemelen halüsinasyonların tekrarlamasının sebeplerinden biridir; çünkü soruyu yanıtlayan kendinden emin bir yanıt, soruyu yanıtlamayan bir yanıta kıyasla daha olumlu bir sonuç olarak pekiştirilmiştir.
Bize göre, rastgele yalan söylemenin cevabı bilmemekten daha kötü olduğu aşikardır; ancak LLM "yalan söylemez." Yalan nedir onu bile bilmiyorlar. Bazıları yapay zekanın hatalarının insan hatalarına benzediğini ve "her şeyi her zaman doğru yapamadığımız için yapay zekanın da aynısını yapmasını beklemememiz gerektiğini" söylüyor. Ancak, yapay zekadan kaynaklanan hataların aslında bizim tarafımızdan tasarlanan kusurlu süreçlerin bir sonucu olduğunu unutmamak önemlidir.
Yapay zeka modelleri bizim gibi yalan söylemez, yanlış anlaşılmalara yol açmaz veya bilgileri yanlış hatırlamaz. Doğruluk veya yanlışlık kavramlarına bile sahip değiller - sadece Bir sonraki kelimeyi bekliyorlar. Olasılıklara dayalı bir cümlede. Neyse ki hâlâ en popüler şeyin doğru şey olma ihtimalinin yüksek olduğu bir durumda olduğumuzdan, bu yeniden yapılandırmalar çoğu zaman doğru bilgileri yansıtıyor. Bu, "doğru cevabı" bulduğumuzda, bunun tasarladığımız bir sonuçtan ziyade rastgele bir yan etki olduğu izlenimini yaratıyor ve işler aslında böyle yürüyor.
Bu modellere internetin tüm bilgisini veriyoruz; ancak onlara hangi bilginin iyi, hangi bilginin kötü, hangi bilginin doğru, hangi bilginin yanlış olduğunu söylemiyoruz; hiçbir şey söylemiyoruz. Ayrıca, kendi başlarına bilgileri ayıklamalarına yardımcı olacak mevcut bir temel bilgileri veya temel ilkeleri de yoktur. Bunların hepsi sadece bir sayı oyunudur; belirli bir bağlamda tekrar tekrar ortaya çıkan kelime kalıpları LLM 'gerçeği' haline gelir. Bana göre bu, çökmeye ve tükenmeye mahkûm bir sistem gibi görünüyor; ancak bazıları bunun AGI'ye yol açacak bir sistem olduğuna inanıyor (bu başka bir tartışma konusu olsa da).
çare nedir?
Sorun şu ki, OpenAI bu gelişmiş modellerin neden bu kadar sık halüsinasyon gördüğünü henüz bilmiyor. Belki Plus araştırmasıyla sorunu anlayıp çözebiliriz, ancak işlerin yolunda gitmeme ihtimali de var. Şirket şüphesiz "gelişmiş" modellerinin Plus ve Plus versiyonlarını yayınlamaya devam edecek ve halüsinasyon oranlarının artmaya devam etme ihtimali var.
Bu durumda OpenAI'nin kök nedene yönelik araştırmalarını sürdürmesinin yanı sıra kısa vadeli bir çözüm arayışına da girmesi gerekebilir. Sonuçta bu modeller gelir getiren ürünler Kullanılabilir durumda olması gerekir. Ben bir yapay zeka bilimcisi değilim, ancak aklıma gelen ilk fikir, bir tür toplayıcı ürün yaratmak olurdu; birden fazla farklı OpenAI modeline erişimi olan bir sohbet arayüzü.
Sorgular ileri düzey akıl yürütme gerektirdiğinde GPT-4o'yu çağırıyorlar, halüsinasyon olasılığını azaltmak istediklerinde ise o1 gibi daha eski bir modeli çağırıyorlar. Belki şirket daha zarif davranıp tek bir sorgunun farklı unsurlarıyla ilgilenmek için farklı modeller kullanabilir ve ardından her şeyi sonunda birbirine bağlamak için ek bir model kullanabilir. Bu, esasen birden fazla yapay zeka modelinin bir ekip çalışması olacağından, belki bir tür gerçek kontrol sistemi de uygulanabilir.
Ancak asıl amaç doğruluk oranlarını artırmak değil. Asıl amaç halüsinasyon oranlarını azaltmaktır, bu da doğru cevap verenlerin yanı sıra "bilmiyorum" cevaplarını da değerlendirmemiz gerektiği anlamına geliyor.
Aslında, OpenAI'nin ne yapacağı veya araştırmacılarının artan halüsinasyon oranı konusunda ne kadar endişeli oldukları hakkında hiçbir fikrim yok. Tek bildiğim, daha fazla halüsinasyonun son kullanıcılar için kötü olduğu; bu, onların farkına bile varmadan bizi yanıltmaları için daha fazla fırsat anlamına geliyor. Eğer LLM modellerinin büyük bir hayranıysanız, onları kullanmayı bırakmanıza gerek yok; ancak zamandan tasarruf etme arzusunun, sonuçları doğrulama ihtiyacını gölgelemesine izin vermeyin. Her zaman doğrulayın!
Yoruma kapalı.