

Meta, yapay zeka modellerine önemli komutları diğerleri ile ayırt etme sanatını öğretiyor.
OpenAI o1 ve DeepSeek-R1 gibi akıl yürütme modellerinin aşırı düşünme sorunu var. Ona "1+1 kaç eder?" gibi basit bir soru sorsanız, cevap vermeden önce birkaç saniye düşünecektir.

İdeal olarak, yapay zeka modelleri, insanlar gibi, ne zaman doğrudan bir cevap vereceklerini ve ne zaman yanıt vermeden önce düşünmek için ek zaman ve kaynak ayıracaklarını belirleyebilmelidir. Ve öyle de yapıyor yeni teknoloji Araştırmacılar tarafından sunuldu meta yapay zeka وChicago'daki Illinois Üniversitesi Sorgu zorluğuna göre çıkarım bütçelerini tahsis etmek için modelleri eğiterek. Bu, daha hızlı yanıtlar, daha düşük maliyetler ve bilgi işlem kaynaklarının daha iyi tahsisi ile sonuçlanır.
pahalı akıl yürütme
Büyük dil modelleri (LLM'ler), genellikle "düşünce zincirleri" (CoT) olarak bilinen daha uzun düşünce zincirleri ürettiklerinde muhakeme görevlerindeki performanslarını artırabilirler. Fikir zinciri tekniğinin başarısı, modelin sorun hakkında daha derinlemesine "düşünmesini", birden fazla yanıt üretip incelemesini ve en iyisini seçmesini zorlayan bir dizi çıkarım zaman ölçekleme tekniğinin ortaya çıkmasına yol açmıştır.
Çoğunluk oyu (ÇO), muhakeme modellerinde kullanılan başlıca yöntemlerden biridir; burada birden fazla yanıt üretilir ve en sık sorulan yanıt seçilir. Bu yaklaşımın sorunu, modelin tekdüze bir davranış benimsemesi, her girdiyi zor bir akıl yürütme problemi olarak ele alması ve birden fazla yanıt üretmek için gereksiz kaynak tüketmesidir.
Akıllı muhakeme
Yeni araştırma makalesi, akıl yürütme modellerinin yanıt vermede daha etkili olmasını sağlayan bir dizi eğitim tekniği öneriyor. İlk adım, modelin belirli bir yanıt belirli sayıda göründüğünde muhakeme sürecini sonlandırdığı “sıralı oylama”dır (SV). Örneğin, formda en fazla sekiz yanıt üretilmesi ve en az üç kez görünen yanıtın seçilmesi isteniyor. Modele yukarıdaki basit sorgu verildiğinde, ilk üç cevabın benzer olması muhtemeldir; bu da erken durdurmaya, zamandan ve hesaplama kaynaklarından tasarrufa yol açacaktır.
Deneyleri, SV'nin aynı sayıda cevap ürettiğinde matematik yarışması problemlerinde klasik MV'den daha iyi performans gösterdiğini göstermektedir. Ancak SV, ek talimatlar ve kod üretimi gerektirdiğinden, kod-hassasiyet oranı açısından MV ile aynı seviyededir.
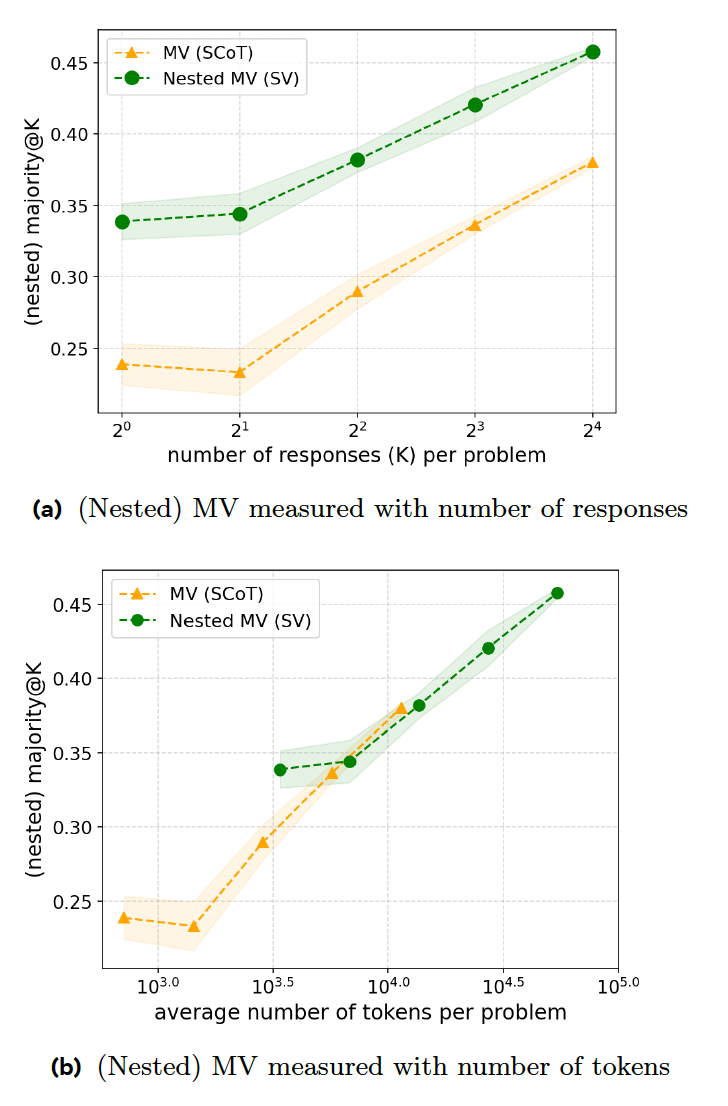
İkinci teknik olan Uyarlanabilir Sıralı Oylama (ASV), modelin sorunu incelemesini ve yalnızca sorun zor olduğunda birden fazla yanıt üretmesini gerektirerek SV'yi iyileştirir. Basit problemler (örneğin 1+1 iddiası) için model oylama sürecinden geçmeden tek bir cevap üretir. Bu, modelin hem basit hem de karmaşık sorunları ele almada daha verimli olmasını sağlar.
Takviyeli öğrenme
Hem SV hem de ASV teknikleri modelin verimliliğini artırırken, büyük miktarda elle etiketlenmiş veri gerektiriyor. Bu sorunu hafifletmek için araştırmacılar, modele sorgu zorluğuna göre muhakeme yollarının uzunluğunu ayarlamayı öğreten bir takviyeli öğrenme algoritması olan "çıkarım bütçesi kısıtlı politika optimizasyonu"nu (IBPO) öneriyorlar.
IBPO, büyük dil modellerinin (LLM) çıkarım bütçesinin kısıtlamaları içinde kalarak yanıtlarını iyileştirmelerine olanak sağlamak için tasarlanmıştır. Takviyeli öğrenme algoritması, ASV yörüngelerini sürekli olarak üreterek, yanıtları değerlendirerek ve doğru yanıtı ve optimum çıkarım bütçesini sağlayan çıktıları seçerek, modelin manuel olarak etiketlenen veriler üzerinde eğitimle elde edilen kazanımları aşmasını sağlar.
Deneyleri, IBPO'nun Pareto cephesini iyileştirdiğini gösteriyor; bu da sabit bir çıkarım bütçesi için IBPO üzerinde eğitilen bir modelin diğer temel çizgilerden daha iyi performans gösterdiği anlamına geliyor.
Bu bulgular, araştırmacıların mevcut yapay zeka modellerinin sıkıntılı olduğu yönündeki uyarılarının ardından geldi. Şirketler yüksek kaliteli eğitim verileri bulmakta ve modellerini iyileştirmek için alternatif yollar keşfetmekte zorlanıyor.
Umut vadeden çözümlerden biri, modele bir hedef verilerek kendi çözümlerini bulmasına izin verilen takviyeli öğrenmedir; bu yöntemde model, elle etiketlenen örneklerle eğitilmektedir.
Şaşırtıcı bir şekilde, model çoğu zaman insanların aklına gelmeyen çözümler buluyor. Bu, Amerikan yapay zeka laboratuvarlarının hakimiyetine meydan okuyan DeepSeek-R1'de işe yaramış gibi görünen bir formül.
Araştırmacılar, "istem tabanlı yöntemler ve SFT'nin mutlak optimizasyon ve verimlilik için mücadele ettiğini, bunun da SFT'nin tek başına kendi kendini düzeltme yeteneklerini etkinleştirmediği varsayımını desteklediğini" belirtiyorlar. Bu gözlem, aynı zamanda, bu kendi kendini düzeltme davranışının istemler veya SFT tarafından manuel olarak oluşturulmak yerine RL sırasında kendiliğinden ortaya çıktığını öne süren eş zamanlı çalışmalarla da destekleniyor.
Yoruma kapalı.