

Açıklama: L1 Düzenlemesi özellikleri otomatik olarak nasıl seçer?
L1 (LASSO) Düzenlemesinin gerçekleştirdiği otomatik özellik seçme sürecini anlayın.
Özellik seçimi, verilen bir özellik kümesinden optimum bir özellik alt kümesini seçme sürecidir; En uygun alt küme, verilen görevde modelin performansını en üst düzeye çıkaran alt kümedir.
Özellik tanımlaması manuel bir işlem olabilir veya daha açık bir şekilde kullanıldığında yapılabilir filtre yöntemleri veya sarmalayıcı yöntemler. Bu yöntemlerde, bir özelliğin tahmin oluşturmada ne kadar önemli olduğunu belirleyen sabit bir metriğin değerine bağlı olarak özellikler yinelemeli olarak eklenir veya kaldırılır. Metrikler bilgi kazanımı, varyans veya ki-kare istatistiği olabilir ve algoritma, metrikteki sabit bir eşik değerini dikkate alarak özelliği kabul etme/reddetme kararını verecektir. Bu yöntemlerin model eğitim aşamasının bir parçası olmadığı ve öncesinde gerçekleştirildiği unutulmamalıdır.
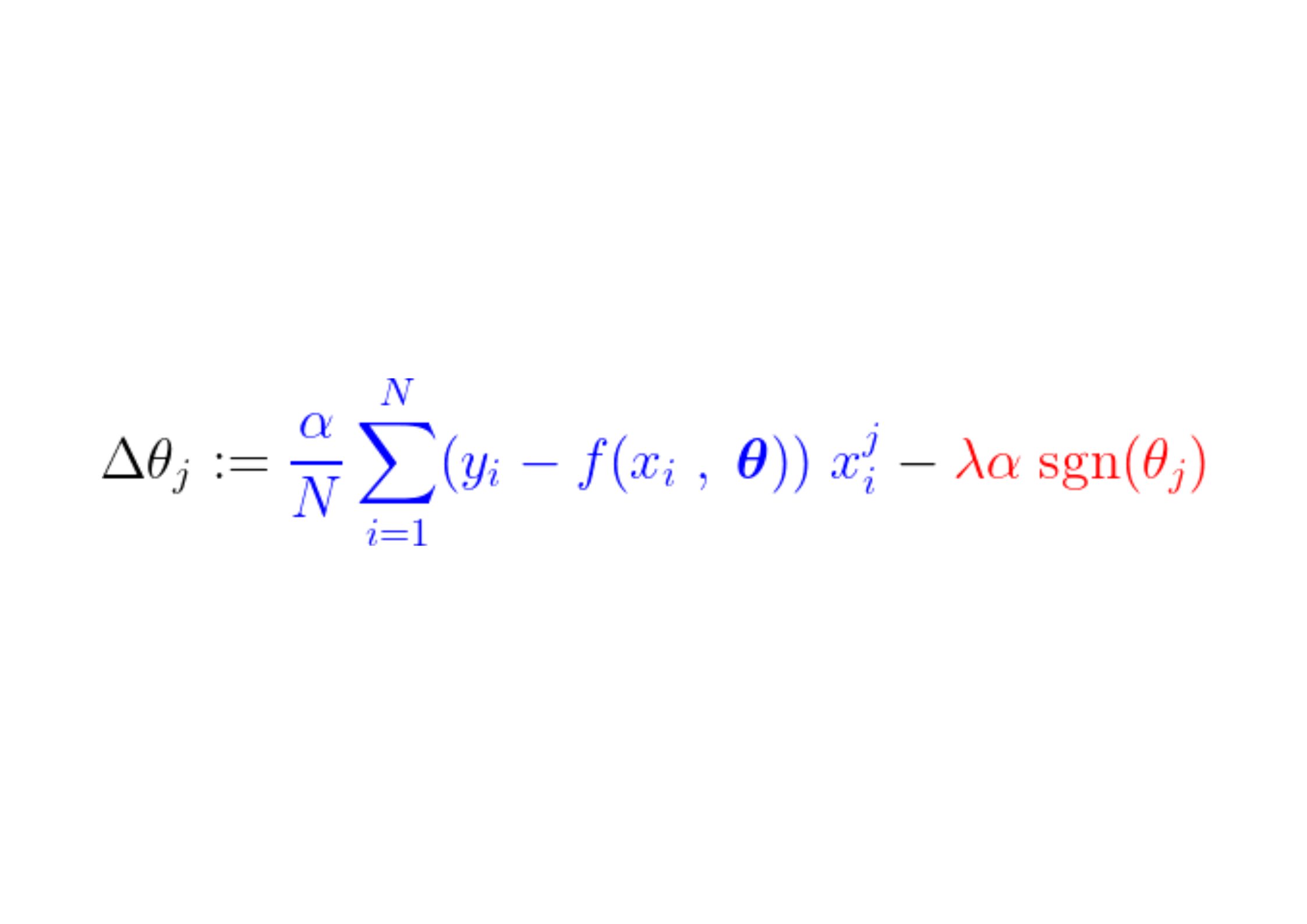
kalkmak Gömülü yöntemler Önceden tanımlanmış herhangi bir seçim kriteri kullanmadan, özellikleri dolaylı olarak seçerek ve bunları eğitim verilerinden çıkararak. Temel özelliklerin belirlenmesi süreci model eğitim aşamasının bir parçasıdır. Model, özellikleri belirlemeyi ve aynı zamanda ilgili tahminlerde bulunmayı öğreniyor. Sonraki bölümlerde, bu temel özellik seçimi sürecinde düzenlemenin rolünü açıklayacağız ve L1 düzenlemesine ve makine öğrenimi modellerini iyileştirmedeki rolüne odaklanacağız.
Normalizasyon ve Model Karmaşıklığı: Performansı İyileştirmek İçin Gelişmiş Stratejiler
Düzenleme, aşırı uyumu önlemek ve göreve genelleme sağlamak için model karmaşıklığını cezalandırma sürecidir.
Burada modelin karmaşıklığı, eğitim verilerindeki desenlere uyum sağlama yeteneğine benzetilmektedir. ' Basit bir polinom modelinin varsayılmasıx'bir dereceye kadar'd'Puan ne kadar yüksekse'dPolinomlar için model, gözlemlenen verilerdeki kalıpları yakalamak adına daha fazla esnekliğe sahiptir. Bu artan esneklik, modelin gerçek örüntüleri öğrenmek yerine eğitim verilerini ezberlemesine yol açabilir; bu da yeni verilere genelleme yapma yeteneğini azaltır.
Aşırı Uyum ve Yetersiz Uyum
Dereceli bir polinom modeline uymaya çalışırken d=2 Gürültülü üçüncü dereceden bir polinomdan alınan bir eğitim örnekleri kümesinde, model örnekleme dağılımını yeterince yakalayamayacaktır. Model basitçe eksik Esneklik أو karmaşıklık Derecesi 3 (veya daha yüksek) polinomlardan üretilen verilerin modellenmesi için gereklidir. Bu modelin şu şekilde olduğu söyleniyor: yetersiz Eğitim verileri üzerine. Az yükleme, modelin çok basit olduğunu ve verilerdeki temel örüntüleri yakalayamadığını gösterir.
Aynı örnek üzerinde çalışarak, şimdi bir dereceye sahip bir modelimiz olduğunu varsayalım. d=6. Artık karmaşıklık arttığından, modelin verileri üretmek için kullanılan orijinal kübik polinomu tahmin etmesi kolay olmalı (örneğin, üs > 3 olan tüm terimlerin katsayılarını 0'a ayarlamak). Eğitim süreci zamanında tamamlanmazsa, model hatayı daha da azaltmak için ek esnekliğini kullanmaya devam edecek ve gürültülü örnekleri de yakalamaya başlayacaktır. Bu, eğitim hatasını büyük ölçüde azaltacaktır, ancak model artık aşırı uyum Eğitim verileri üzerine. Gerçek dünya koşullarında (veya test aşamasında) gürültü değişecek ve tahmine dayalı her türlü bilgi bozulacak, bu da yüksek test hatasına yol açacaktır. Aşırı yükleme, modelin çok karmaşık olması ve gerçek sinyal yerine gürültüyü öğrenmesi anlamına gelir.
Modelin optimum karmaşıklığı nasıl belirlenir?
Pratik durumlarda, veri üretim süreci veya verilerin gerçek dağıtımı hakkında genellikle sınırlı veya hiç bilgimiz yoktur. Uygun karmaşıklığa sahip, aşırı veya yetersiz uyumun olmadığı optimum modeli bulmak önemli bir zorluktur. Bu, modellerin performansını değerlendirmek ve doğruluk ile genellik arasında en iyi dengeyi sağlayan uygun karmaşıklığı belirlemek için etkili yöntemlerin kullanılmasını gerektirir. Profesyoneller, çapraz doğrulama gibi uygun değerlendirme ölçütlerini ve tekniklerini kullanarak, görülmemiş veriler üzerinde en iyi performansı gösteren modeli belirleyebilir ve böylece aşırı veya yetersiz uyum sorunlarından kaçınabilirler.
Mümkün olan bir teknik, yeterince sağlam bir modelle başlamak ve daha sonra özellik seçimiyle karmaşıklığını azaltmaktır. Özellik sayısı ne kadar azsa model o kadar az karmaşıktır.
Önceki bölümde tartıştığımız gibi, özellik seçimi açık (filtreleme yöntemleri, evrişim yöntemleri) veya örtük olabilir. Hedef değişkenin değerini belirlemede çok önemli olmayan gereksiz özellikler, bunlarda model öğrenme ilişkisiz örüntülerinin oluşmasını önlemek için kaldırılmalıdır. Düzenleme de benzer bir görevi yerine getirir. Peki, düzenleme ve özellik seçimi, optimal model karmaşıklığı ortak hedefine ulaşmada nasıl bir ilişkiye sahiptir? Makine öğrenimi modellerindeki karmaşıklığı azaltmak, performansı iyileştirmek ve aşırı uyumu önlemek için çok önemlidir; bu, hem düzenlemenin hem de özellik seçiminin odaklandığı konudur.
L1 düzenlemesi bir özellik belirleyicisi olarak
Polinom modelimize devam ederek, bunu girişleri f olan bir fonksiyon olarak gösteriyoruz. xve işlemler θ ve derece d،
![]()
Polinom bir model için, girdinin her bir kuvveti düşünülebilir x_i Avantaj olarak, aşağıdaki formda bir vektör oluşturmak için:
![]()
Ayrıca, optimum parametrelere ulaşmamızı sağlayacak olan minimumu belirleyen bir amaç fonksiyonu da tanımlıyoruz. θ* Terim şunları içerir: düzenleme (Yönetmelik) Model karmaşıklığını cezalandıran.
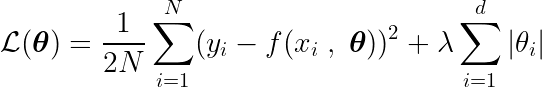
Bu fonksiyonun minimumunu bulmak için tüm kritik noktaları, yani türevin sıfır olduğu veya tanımsız olduğu noktaları analiz etmemiz gerekir.
Kısmi türev, parametrelerden birine göre yazılabilir, θj, bu şekilde:
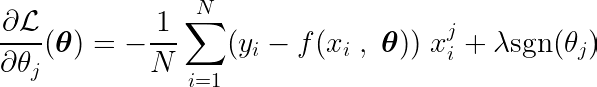
fonksiyonun tanımlandığı yer imza bu şekilde:
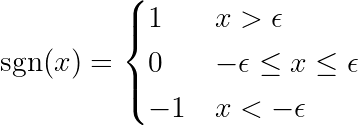
ملاحظةMutlak bir fonksiyonun türevi yukarıda tanımlanan işaret fonksiyonundan (sgn) farklıdır. Orijinal türev x = 0'da tanımsızdır. Tanımı, x = 0'daki dönüm noktasını kaldıracak ve fonksiyonu tüm değer aralığı üzerinde türevlenebilir hale getirecek şekilde genişletiyoruz. Ayrıca, makine öğrenimi (ML) çerçeveleri, temel hesaplamalar mutlak fonksiyonu içerdiğinde bu genişletilmiş fonksiyonları kullanır. Şuna bir bakın! bağlantı PyTorch forumunda.
Tek bir katsayıya göre hedef fonksiyonun kısmi türevini hesaplayarak θjve bunu sıfıra eşitleyerek, optimum değeri birbirine bağlayan bir denklem oluşturabiliriz. θj Tahminler, hedefler ve özellikler ile.
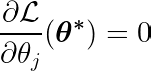
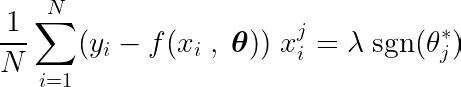
Yukarıdaki denklemi inceleyelim. Girişlerin ve hedeflerin ortalama etrafında merkezlendiğini varsayarak (yani, veriler ön işleme adımında standartlaştırılmıştır), sol taraftaki terim (LHS) etkili bir şekilde şunu temsil eder: varyans Özellik numarası j ile beklenen ve hedef değerler arasındaki fark arasında.
İki değişken arasındaki istatistiksel kovaryans, bir değişkenin ikinci değişkenin değeri üzerindeki etki miktarını belirler (veya tersi).
Sağ taraftaki işaret fonksiyonu, sol taraftaki değişimin yalnızca üç değer almasını zorlar (çünkü işaret fonksiyonu yalnızca -1, 0 ve 1 değerini döndürür). Eğer özellik j Gereksizdir ve tahminleri etkilemez, varyans sıfıra yakın olacaktır, bu da karşılık gelen katsayıyı yapar θj* Sıfır. Bu, özelliğin modelden kaldırılmasıyla sonuçlanır. Bu süreç karmaşıklığın azaltılmasına ve model performansının iyileştirilmesine yardımcı olur.
İşaretin işlevini suyun oyduğu bir oluk olarak düşünün. Dere yatağına doğru yürüyebilirsiniz, ancak dereden çıkmak için büyük bariyerlerle veya dik akıntılarla karşılaşacaksınız. L1 düzenlemesi, kayıp fonksiyonunun gradyanına benzer bir “eşik” etkisi yaratır. Eğimin bariyerleri yıkacak kadar güçlü olması veya sıfıra inmesi, en sonunda katsayı değerinin sıfır olmasını sağlaması gerekir.
Daha gerçekçi bir örnek vermek gerekirse, düz bir çizgiden türetilen örnekleri (iki faktörlü parametrelendirilmiş) ve biraz gürültü eklenmiş bir veri kümesini ele alalım. En uygun model iki parametreden fazlasına sahip olmamalıdır, aksi takdirde verilerdeki gürültüye aşırı uyum sağlar (polinomun ek özgürlüğü/gücüyle). Polinom modelindeki yüksek güç katsayılarının değiştirilmesi, hedefler ile model tahminleri arasındaki farkı etkilemez ve dolayısıyla bunların özellik ile olan varyansını azaltır.
Eğitim süreci sırasında kayıp fonksiyonunun gradyanına sabit bir adım eklenir/çıkarılır. Kayıp fonksiyonunun eğimi (MSE – ortalama kare hatası) sabit adımdan daha küçükse, katsayı sonunda 0 değerine ulaşacaktır. Aşağıdaki denklemde katsayıların eğim inişi kullanılarak nasıl güncellendiği gösterilmektedir:

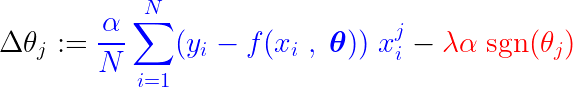
Yukarıdaki mavi kısım daha küçükse λα, kendi başına çok küçük bir sayıdır, o zaman Δθj Neredeyse istikrarlı bir adım. λα. Bu adımın (kırmızı kısım) sinyali şunlara bağlıdır: işaret(θj)çıktısı neye bağlıdır θj. Eğer değer ise θj Pozitif, yani 'den büyük ε, işaret(θj) 1'e eşit olduğundan, Δθj Yaklaşık olarak eşittir -λα, onu sıfıra doğru itiyor.
Katsayıyı sıfır yapan sabit adımı (kırmızı kısım) bastırmak için, kayıp fonksiyonunun gradyanı (mavi kısım) adım boyutundan büyük olmalıdır. Kayıp fonksiyonu için daha büyük bir eğim elde etmek için, özellik değerinin model çıktısını önemli ölçüde etkilemesi gerekir.
Bu sayede, eğitim sırasında özelliğin veya daha doğrusu ona karşılık gelen, değeri model çıktısıyla ilişkili olmayan parametrenin L1 düzenlemesi ile sıfırlanması sağlanıyor.
Daha fazla okuma ve sonuç
- Bu konu hakkında daha fazla bilgi edinmek için Reddit r/MachineLearning'de bir soru yayınladım veTakip et İçerisinde okumak isteyebileceğiniz farklı yorumlar da yer alıyor.
- Madiyar Aitbayev'in de ilginç blog Aynı soruyu, mühendislik açıklamasıyla ele alıyor.
- Blog Brian King organizasyonu olasılıkçı bir bakış açısıyla açıklıyor.
- bu النقاش CrossValidated web sitesinde L1 kriterinin neden seyrek modelleri teşvik ettiğini açıklıyor. Blog Mukul Ranjan'ın yazdığı detaylı bir makale, L1 normunun işlemlerin sıfır olmasını teşvik ederken, L2 normunun bunu yapmamasının nedenini açıklıyor.
"L1 Düzenlemesi özellikleri seçer" ifadesi, ML öğrenenlerin çoğunun hemfikir olduğu basit bir ifadedir; ancak dahili olarak nasıl çalıştığına değinilmemiştir. Bu blog, okuyuculara soruyu sezgisel bir şekilde cevaplayabilmek için anlayışımı ve zihinsel modelim sunma girişimidir. Öneri ve şüpheleriniz için e-postamı şu adreste bulabilirsiniz: Benim web sitem. Öğrenmeye devam edin ve harika bir gün geçirin!
Yoruma kapalı.